图提示学习综述:Graph Prompting 最新进展与未来方向
论文信息
- 标题: Graph Prompting for Graph Learning Models: Recent Advances and Future Directions
- 作者: Xingbo Fu, Zehong Wang, Zihan Chen et al. (University of Virginia, University of Notre Dame, University of Connecticut)
- 会议: KDD ‘25 (ACM SIGKDD 2025 Tutorial/Survey Track)
- arXiv: 2506.08326
- 代码: 暂无
一句话总结
本文系统性地综述了图提示学习(Graph Prompting)的最新进展,提出了从图数据、节点表示到下游任务的三层分类体系,总结了图预训练方法、提示技术分类、实际应用场景,并指出了基准构建、理论基础、通用兼容性等未来研究方向。
背景与动机
图结构数据广泛存在于生物信息学、社交网络、推荐系统等真实场景中。图神经网络(GNN)和图 Transformer 等图学习模型在这些领域取得了显著成功。然而,传统的监督学习方法存在两个关键局限:
- 依赖大量标注数据:监督学习需要充足的标签,但真实场景中标注成本高昂
- 泛化能力有限:在一个任务上训练的模型难以直接迁移到其他下游任务
为了解决这些问题,”预训练 - 适配“方案应运而生。该方案首先在无标签图数据上进行自监督预训练,然后在具体下游任务上进行适配。在适配阶段,图提示学习(Graph Prompting)作为一种新兴方法,通过学习可训练的提示向量,同时保持预训练模型参数冻结,实现了高效的模型适配。
与微调(Fine-tuning)相比,图提示学习具有显著优势:
- ✅ 参数高效:仅需更新极少量提示参数,适合少样本场景
- ✅ 灵活性强:可在不同层级(数据层、表示层、任务层)设计提示
- ✅ 避免灾难性遗忘:预训练知识得以完整保留
这些优势使得图提示学习成为图学习领域的热门研究方向,吸引了学术界和工业界的广泛关注。
核心方法
整体框架
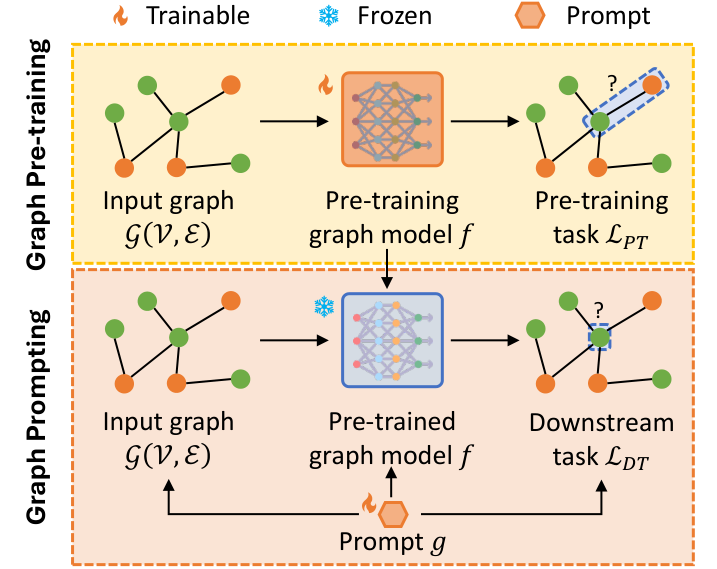 图 1:”预训练 - 提示”方案的工作流程。首先在无标签数据上预训练图学习模型,然后通过可训练提示向量适配到下游任务,同时保持预训练模型冻结。
图 1:”预训练 - 提示”方案的工作流程。首先在无标签数据上预训练图学习模型,然后通过可训练提示向量适配到下游任务,同时保持预训练模型冻结。
图提示学习的核心思想是:在预训练模型的基础上,引入可学习的提示向量(Prompt Vectors),通过调整这些提示来适配下游任务,而预训练模型的参数保持冻结。
图预训练方法
图预训练是图提示学习的基础。根据获取不变性的机制不同,现有方法可分为三类:
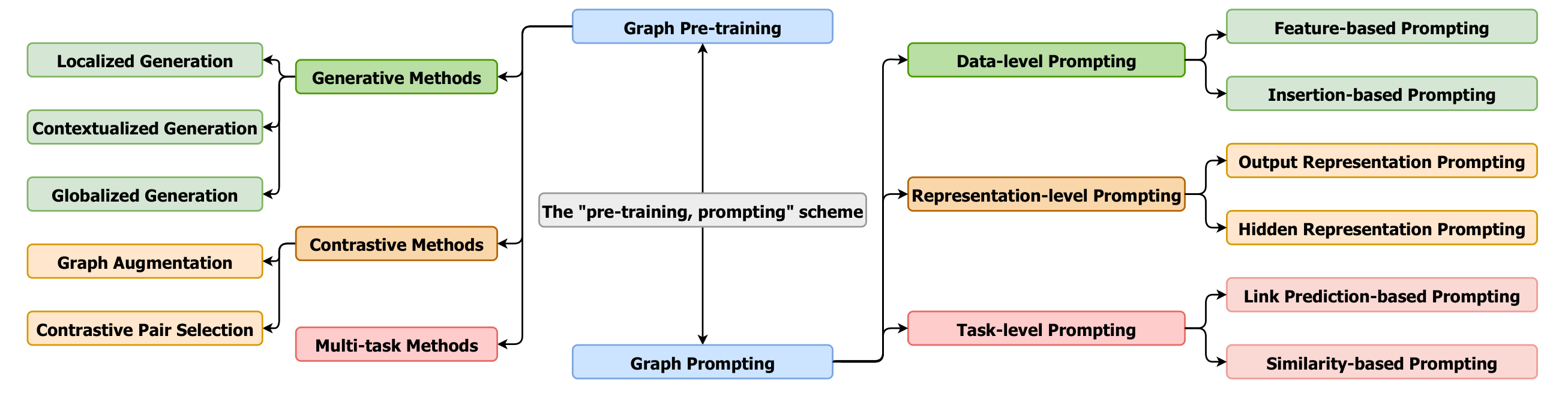 图 2:图预训练和图提示技术的分类体系。预训练方法包括生成式、对比式和多任务学习;提示技术分为数据层、表示层和任务层。
图 2:图预训练和图提示技术的分类体系。预训练方法包括生成式、对比式和多任务学习;提示技术分为数据层、表示层和任务层。
1. 生成式方法(Generative Methods)
生成式方法遵循”去噪”哲学:对输入图进行部分破坏,然后训练模型恢复原始信息。形式化定义为:
\[\min_{\theta} \ell(f(\tilde{\mathcal{G}}; \theta), \rho(\mathcal{G}))\]其中 $\tilde{\mathcal{G}} = \mathcal{C}(\mathcal{G})$ 是被破坏的图,$\rho(\mathcal{G})$ 是重建目标。根据生成目标的粒度,可分为:
- 局部生成(Localized):重建节点属性或预测节点性质,如 GraphMAE 通过节点掩码重建特征
- 上下文生成(Contextualized):预测节点周围的结构信息,如边预测、子图重构
- 全局生成(Globalized):保持整个图的性质,如图相似性学习
2. 对比式方法(Contrastive Methods)
对比式方法通过区分相似和不相似实例进行预训练。核心流程包括:
- 图增强:对原图应用变换生成多个增强视图
- 特征增强:节点特征掩码、特征打乱
- 结构增强:边扰动、边扩散
- 采样增强:子图采样、随机游走
- 对比对选择:
- 同尺度对比:节点 - 节点、图 - 图
- 跨尺度对比:节点 - 图、子图 - 全局
- 对比目标:最大化正样本对互信息,最小化负样本对互信息,常用 InfoNCE 损失
3. 多任务方法(Multi-task Methods)
通过多任务学习进行预训练,如同时执行节点级任务(属性掩码、上下文预测)和图级任务(图属性预测、结构相似性)。
图提示技术分类
根据提示作用阶段的不同,本文将图提示技术分为三大类:
1. 数据层提示(Data-level Prompting)
数据层提示通过修改输入图数据来适配下游任务。给定输入图 $\mathcal{G} = (\mathbf{A}, \mathbf{X})$,学习转换函数 $\mathcal{T}^D$ 生成提示后的图:
\[(\tilde{\mathbf{A}}, \tilde{\mathbf{X}} ) = \mathcal{T}^D \left(\left(\mathbf{A}, \mathbf{X}\right); \mathcal{P}\right)\]根据修改组件的不同,分为:
特征基提示(Feature-based Prompting):
- 为每个节点学习提示向量并加到特征上:$\tilde{\mathbf{x}}_i = \mathbf{x}_i + \mathbf{p}_i$
- 代表方法:
- GPF:所有节点共享同一提示向量
- GPF-plus:使用基向量的加权组合,更参数高效
- SUPT、IAGPL:基于子图或节点感知的权重计算
- RELIEF:使用强化学习选择需要提示的节点
- HetGPT:扩展到异构图,为不同节点类型设计专用提示
- DyGPrompt:扩展到动态图,生成节点和时间双重视图提示
插入基提示(Insertion-based Prompting):
- 向原图中插入额外的提示节点
- 代表方法:
- SGL-PT、PSP:插入的提示节点与所有原图节点均匀连接
- All-in-one:通过点积定义插入模式,支持多提示节点
- VNT:针对图 Transformer,将提示节点与原图节点拼接
局限性:数据层提示需要在每次更新时执行完整的前向和后向传播,计算成本较高。
2. 表示层提示(Representation-level Prompting)
表示层提示直接修改节点表示(输出表示或隐藏表示)。给定第 $l$ 层的表示 $\mathbf{H}^{(l)}$:
\[\tilde{\mathbf{H}}^{\left( l \right)} = \mathcal{T}^R \left(\mathbf{H}^{\left( l \right)}; \mathcal{P}\right)\]根据作用层级的不同,分为:
输出表示提示(Output Representation Prompting):
- 对最终层输出进行逐元素加权:$\tilde{\mathbf{h}}^{\left( L \right)}_i = \mathbf{p}_i \odot \mathbf{h}^{\left( L \right)}_i$
- 代表方法:
- GraphPrompt:所有节点共享通用提示向量
- ProNoG:使用条件网络为每个节点生成个性化提示,特别适合异配图
隐藏表示提示(Hidden Representation Prompting):
- 为每一层学习独立的提示向量
- 代表方法:
- GraphPrompt+:为每层(包括输入层)学习提示向量
- EdgePrompt+:为每条边学习定制化提示向量,通过消息传递聚合
优势:输出表示提示只需最终输出,更灵活且计算高效;隐藏表示提示通过层间提示增强适配能力,但不适用于黑盒模型。
3. 任务层提示(Task-level Prompting)
任务层提示将下游任务重新表述为其他形式,特别适合少样本场景。
基于链接预测的提示(Link Prediction-based Prompting):
- 将节点分类转换为链接预测任务
- 为每个类别学习提示向量,与节点表示组合作为预训练投影头的输入
- 代表方法:GPPT
- 局限:仅兼容链接预测预训练任务,且只适用于分类任务
基于相似度的提示(Similarity-based Prompting):
- 使用对比损失比较图表示与类别原型
- 优化目标: \(\min_{\mathcal{P}} \sum_{\left( x, y \right) \in \mathcal{D}} - \log \frac{\exp\left(\text{sim} \left( \mathbf{h}_x, \mathbf{s}_y \right) / \tau \right)}{\sum_{c \in \mathcal{Y}} \exp\left(\text{sim} \left( \mathbf{h}_x, \mathbf{s}_c \right) / \tau \right)}\)
- 代表方法:GraphPrompt、GraphPrompt+、MultiGPrompt、HetGPT
- 局限:同样仅适用于分类任务
实验结果
方法对比总结
| 技术类别 | 提示阶段 | 提示策略 | 单次前向传播 | 任务通用性 | 代表工作 |
|---|---|---|---|---|---|
| 数据层提示 | 图数据 | 特征基提示 | ❌ | ✅ | GPF-plus, IAGPL, HetGPT, DyGPrompt |
| 插入基提示 | ❌ | ✅ | PSP, All-in-one, VNT, SGL-PT | ||
| 表示层提示 | 节点表示 | 输出表示提示 | ✅ | ✅ | GraphPrompt, ProNoG |
| 隐藏表示提示 | ❌ | ✅ | EdgePrompt+, GraphPrompt+ | ||
| 任务层提示 | 下游任务 | 链接预测基提示 | ✅ | ❌ | GPPT |
| 相似度基提示 | ✅ | ❌ | GraphPrompt, MultiGPrompt, HetGPT |
关键发现:
- ✅ 表示层提示中的输出表示提示同时支持单次前向传播和任务通用性,最为灵活
- ✅ 数据层提示参数较多但表达能力强,适合复杂场景
- ❌ 任务层提示受限于任务类型,仅适用于分类任务
AI 分析方法亮点
问题定位精准
这篇综述直击图学习领域的核心痛点:预训练与下游任务之间的目标鸿沟。作者敏锐地指出,传统的”预训练 - 微调”范式在图数据上存在天然缺陷——预训练任务(如链接预测)与下游任务(如节点分类)的学习目标不一致,导致模型性能受损。图提示学习通过冻结预训练模型、仅更新提示参数的策略,巧妙规避了这一难题。
更关键的是,论文明确指出图数据的特殊性:非欧几里得结构使得提示设计可以在数据层、表示层、任务层三个维度展开,这比 NLP 中的提示学习灵活得多。
方法创新
本文提出了三层分类体系(数据层、表示层、任务层),这是现有图提示综述中最为清晰的组织框架。核心创新点包括:
- 系统性对比:表格总结了 15+ 种方法的特性(单次前向传播、任务通用性等),发现输出表示提示同时满足高效性和通用性
- 技术细节完整:每个方法都给出了数学公式,如相似度提示的对比损失函数
- 覆盖全面:从生成式/对比式/多任务预训练,到特征基/插入基提示,再到链接预测/相似度任务转换
值得注意的是,论文明确指出任务层提示只能处理分类任务的局限性,这种坦诚在综述文章中并不多见。
实用性强
图提示学习的参数高效性(<1% 可训练参数)使其在真实场景中具有显著优势:
- 推荐系统:PGPRec、GraphPro 已实现跨域推荐和动态偏好建模
- 知识图谱:KGTransformer、MUDOK 支持跨图谱迁移,避免重复训练
- 生物医药:MolCPT、MOAT 在分子属性预测中处理稀缺标注
论文指出的未来方向(统一基准、理论分析、LLM 融合)为工程实践提供了明确指引。对于从业者而言,输出表示提示是最值得优先尝试的技术路线。
总结
图提示学习作为连接预训练图模型和下游任务的桥梁,正在成为图学习领域的重要研究方向。本文系统性地综述了该领域的最新进展:
核心贡献:
- ✅ 提出了从图数据、节点表示到下游任务的三层分类体系
- ✅ 总结了生成式、对比式、多任务三类预训练方法
- ✅ 梳理了推荐系统、知识工程、生物医药等领域的实际应用
- ✅ 指出了基准构建、理论基础、通用兼容性等未来方向
未来展望:
- 🔮 建立统一的基准测试套件,实现公平比较
- 🔮 发展基于图论的理论框架,指导提示设计
- 🔮 开发通用兼容性框架,适配不同图结构和任务
- 🔮 探索与大语言模型的深度融合,利用 LLM 的推理能力优化提示
随着研究的深入,图提示学习有望在更多真实场景中发挥关键作用,成为图学习模型高效适配的标准范式。
参考链接
- 论文原文:arXiv:2506.08326
- KDD ‘25 论文集:DOI: 10.1145/3711896.3736566
- 相关综述:A Survey of Graph Prompting
- GraphMAE: arXiv:2205.10803
- GPPT: arXiv:2205.13172