Loop Engineering 14 步路线图:以及 Codex /goal 在哪里最有用
参考链接 X 原始文章 王若风的技术博客整理版 一句话总结 Loop Engineering 不是“把 prompt 写得更长”,而是把 Agent 的工作发现、执行、验证、记录和下一步决策做成一个可持续运行的闭环;Codex /goal 则更像这个闭环在单次 coding session 里的最小可行入口。 为什么现在该从 Prompt 走向 Loo...
参考链接 X 原始文章 王若风的技术博客整理版 一句话总结 Loop Engineering 不是“把 prompt 写得更长”,而是把 Agent 的工作发现、执行、验证、记录和下一步决策做成一个可持续运行的闭环;Codex /goal 则更像这个闭环在单次 coding session 里的最小可行入口。 为什么现在该从 Prompt 走向 Loo...
参考资料 文档: Thinking in LangGraph 重点章节: Keep state raw, format prompts on-demand 一句话总结 LangGraph 的核心不是“把一个大 Prompt 交给模型”,而是先把任务拆成一组职责明确的节点,再通过共享状态把这些节点串起来。这个过程中最重要的设计原则之一是:State 里保存原始...
一句话总结 在语言模型训练中,entropy 衡量的是模型对下一个 token 概率分布的“不确定性”:熵越高,说明概率越分散、模型越犹豫;熵越低,说明概率越集中、模型越自信。 什么是熵 熵(Entropy)来自信息论,用来衡量一个概率分布的不确定性。 放到语言模型里,它描述的是:模型在预测“下一个 token”时,到底是很确定地把概率压在少数 token 上,还是把概率分散给了...
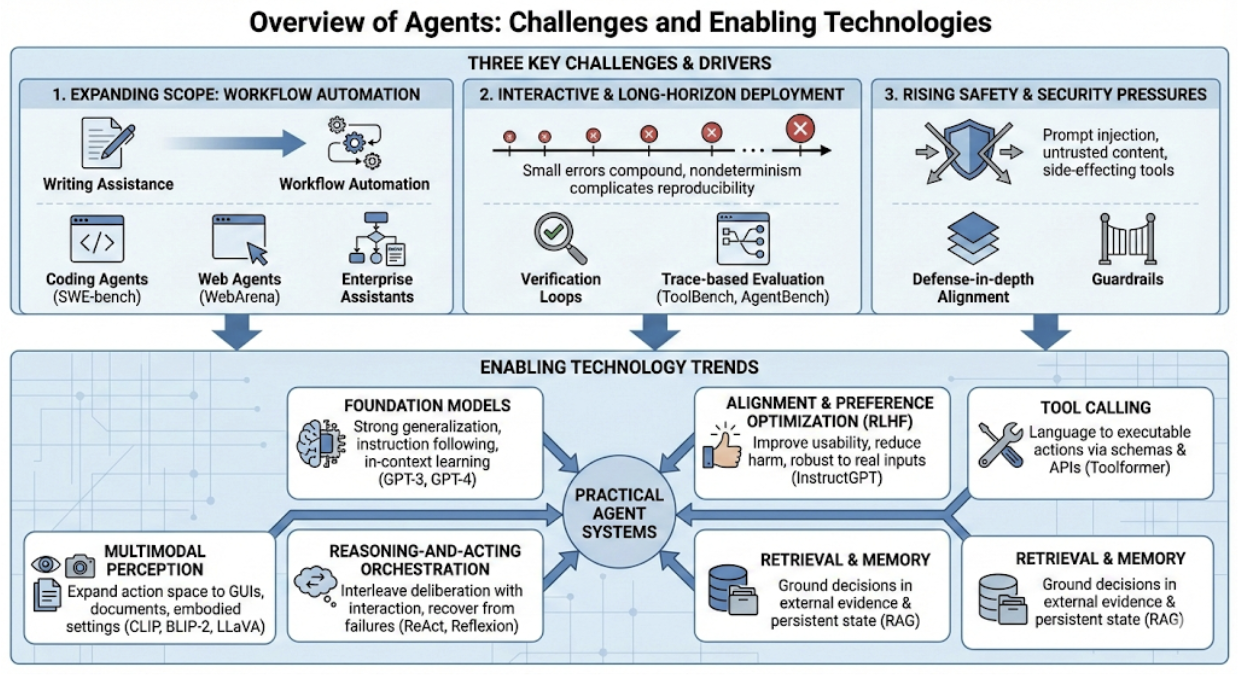
论文信息 标题: AI Agent Systems: Architectures, Applications, and Evaluation 作者: Bin Xu (Arizona State University) 发布: 2025 arXiv: 2601.01743 一句话总结 本文系统性综述了 AI Agent 系统的完整技术栈,提...
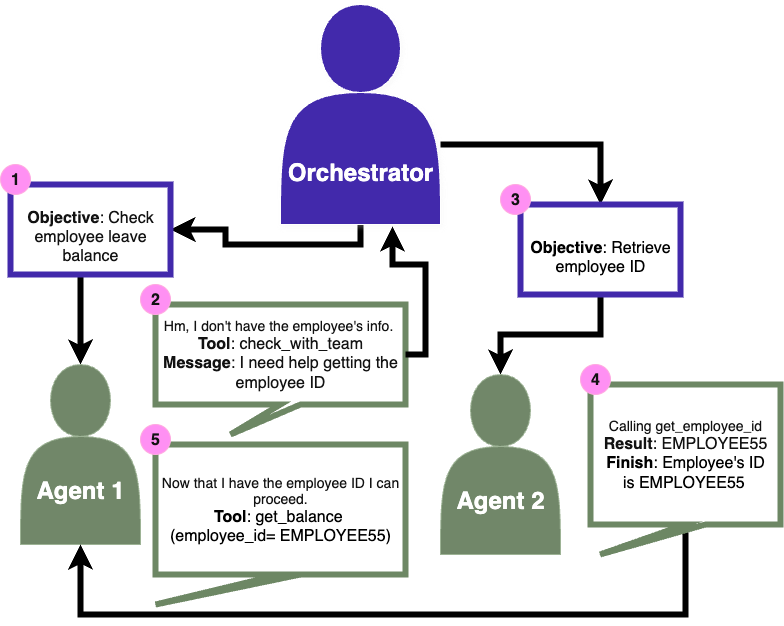
论文信息 标题: AgentArch: A Benchmark for Evaluating Agent Architectures in Enterprise Workflows 作者: Tara Bogavelli, Hari Subramani, Roshnee Sharma (ServiceNow) 发布: 2025 GitHub: Servic...
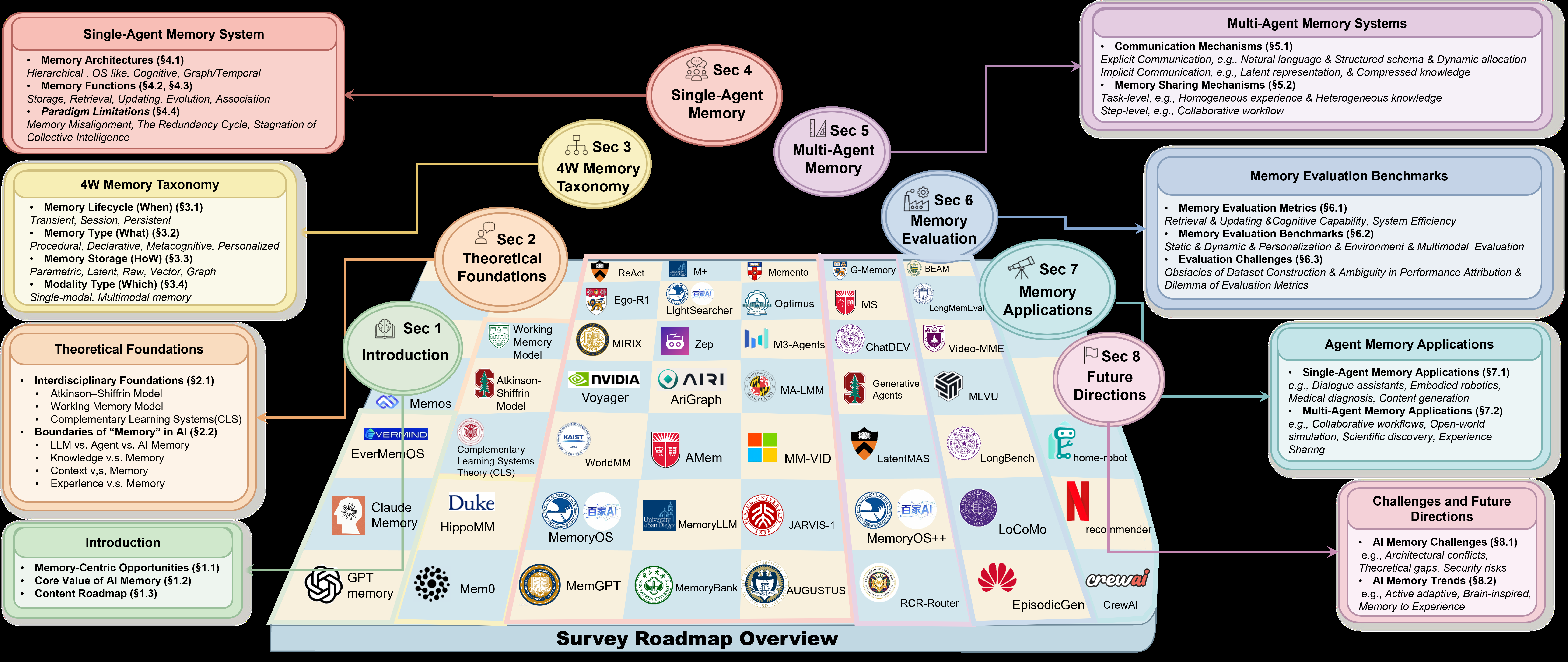
论文信息 标题: Survey on AI Memory: Theories, Taxonomies, Evaluations, and Emerging Trends 作者: Ting Bai, Jiayang Fan, Xiaoshuai Wen et al. 机构: BaiJia AI Team, 北京邮电大学,华为技术有限公司 发布: 2026/...
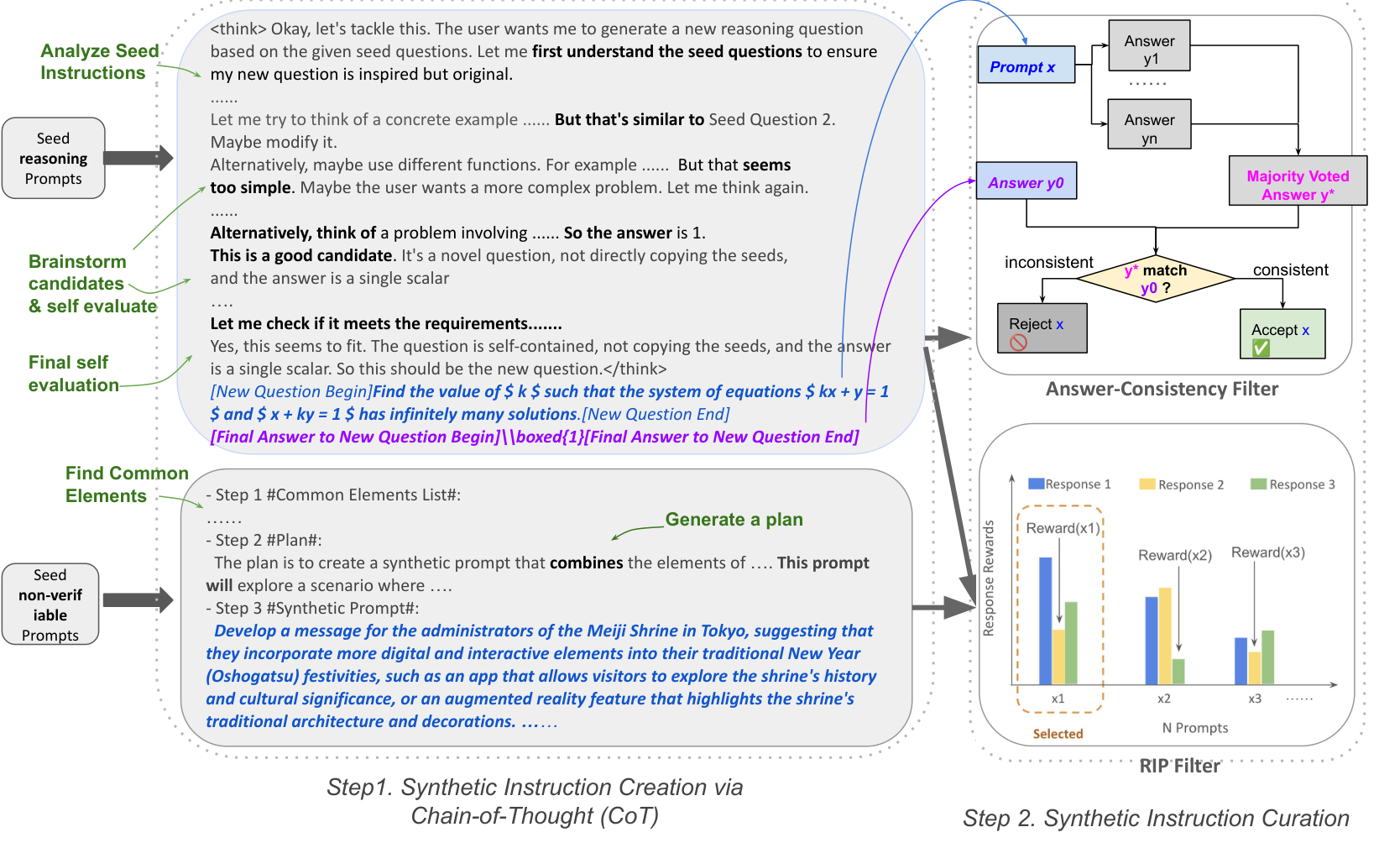
论文信息 标题: CoT-Self-Instruct: Building High-Quality Synthetic Data for Reasoning and Non-Reasoning Tasks 作者: Ping Yu et al. (FAIR at Meta, NYU) 会议: ICLR 2025 arXiv: 2507.23751 ...
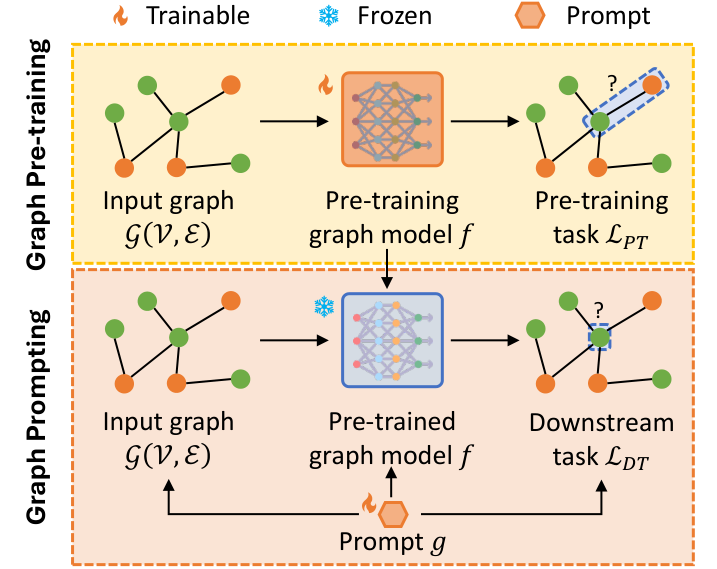
论文信息 标题: Graph Prompting for Graph Learning Models: Recent Advances and Future Directions 作者: Xingbo Fu, Zehong Wang, Zihan Chen et al. (University of Virginia, University of Notre Dame,...
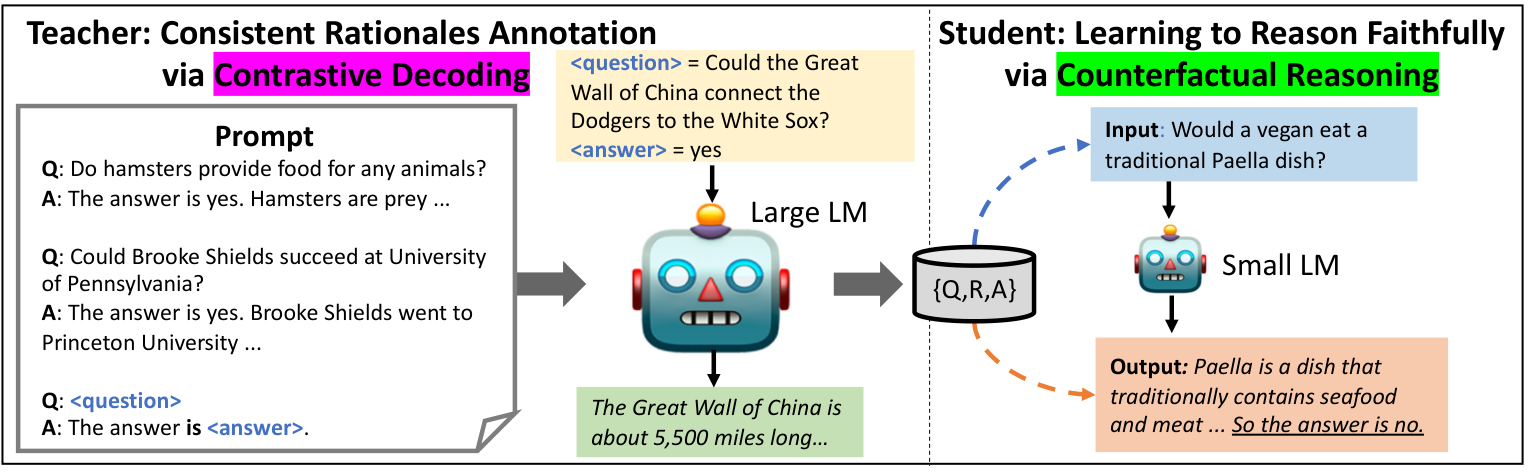
论文信息 标题: SCOTT: Self-Consistent Chain-of-Thought Distillation 作者: Peifeng Wang et al. (USC, Amazon) 会议: ACL 2023 arXiv: 2305.01879 代码: GitHub 📊 本文插图 Figure 1: GP...
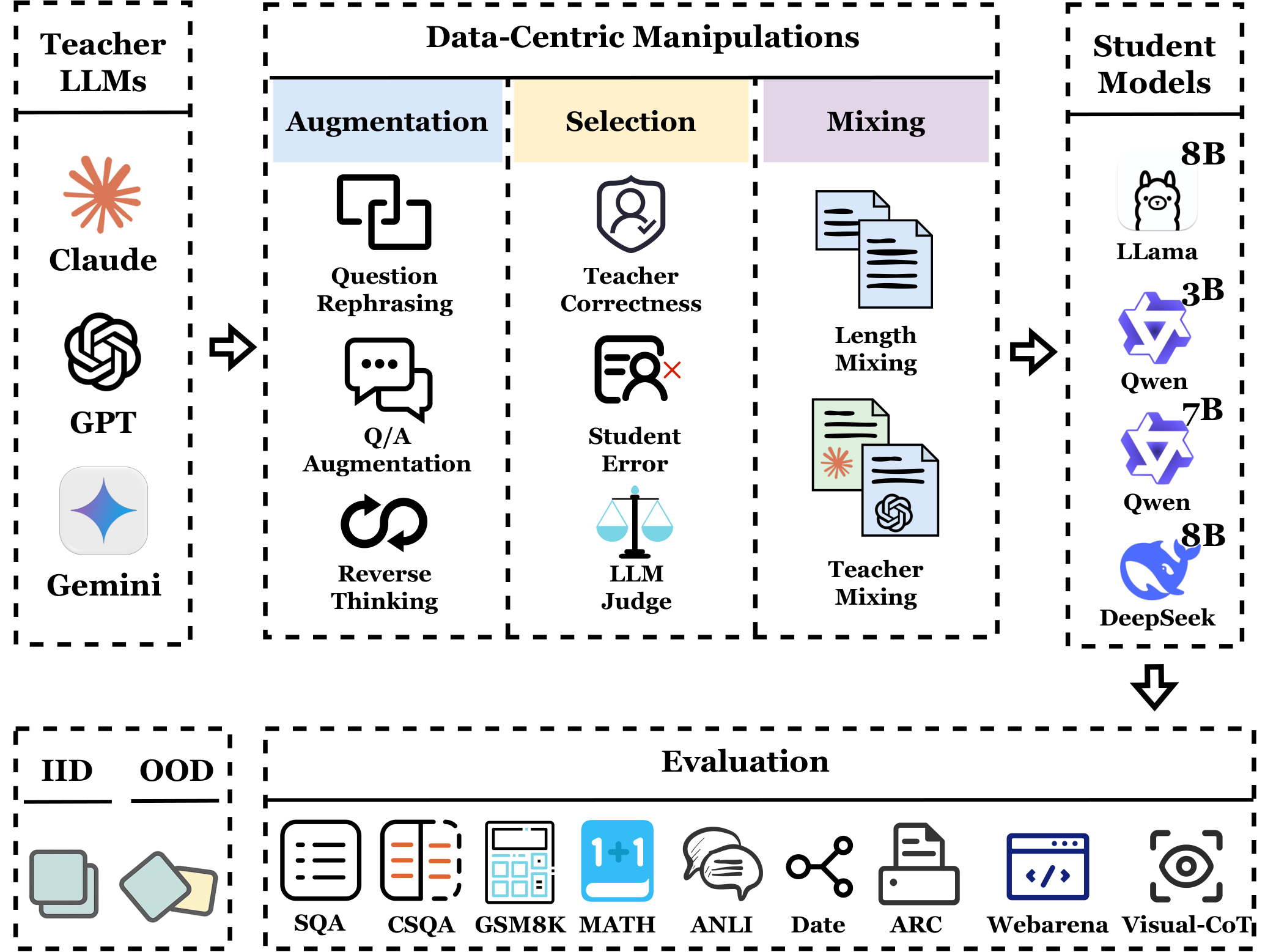
论文信息 标题: The Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation 作者: Ruichen Zhang et al. (UNITES Lab) arXiv: 2505.18759 代码: GitHub - Distillation-Bench ...