AI Agent 系统综述:架构、应用与评测全景指南
论文信息
- 标题: AI Agent Systems: Architectures, Applications, and Evaluation
- 作者: Bin Xu (Arizona State University)
- 发布: 2025
- arXiv: 2601.01743
一句话总结
本文系统性综述了 AI Agent 系统的完整技术栈,提出了统一的”Agent Transformer“抽象框架,涵盖架构设计、学习策略、应用领域和评测方法,为从业者和研究者提供了全面的实践指南。
背景与动机
基础模型已将自然语言转化为计算接口,但真实任务远非单轮问答。它们需要:
- 从多源收集信息并维护状态
- 在约束条件下(延迟、权限、安全、成本)选择工具并执行多步操作
- 验证结果并从错误中恢复
AI Agent 正是为填补这一缺口而生:它将基础模型与执行循环耦合,能够观察环境、规划、调用工具、更新记忆并验证结果。
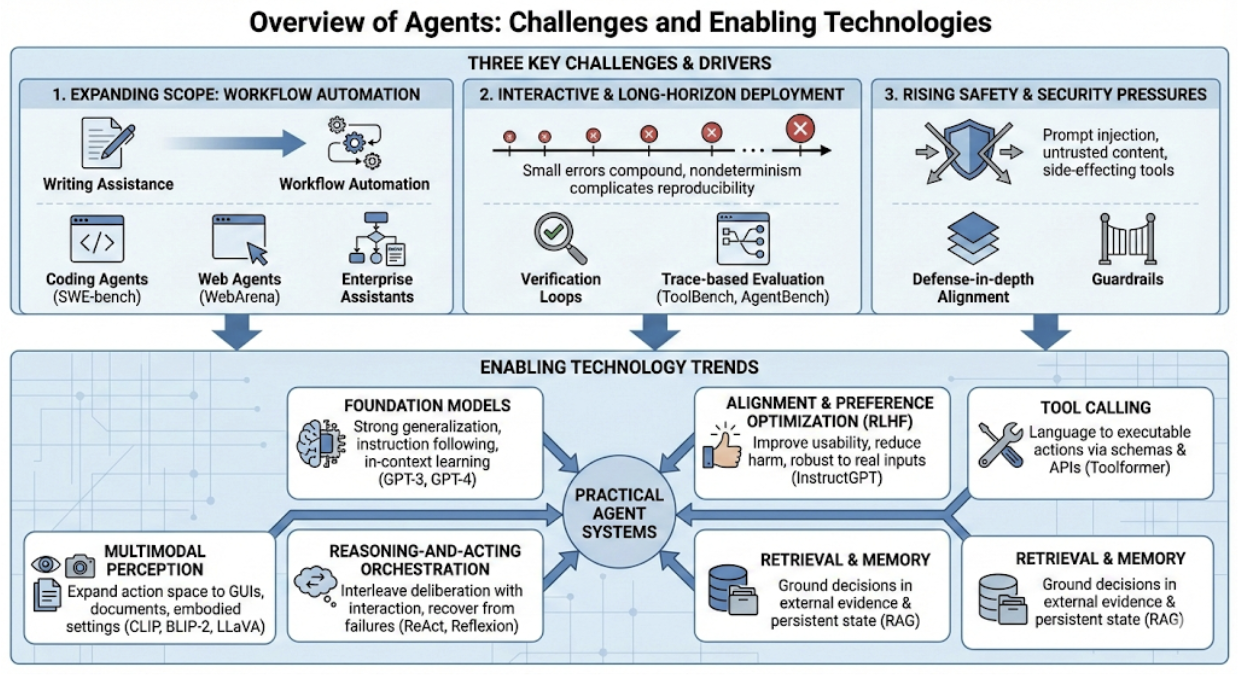
为什么 Agent 在此时至关重要?
- 任务范围扩展:从写作辅助转向工作流自动化(代码、网页、企业系统)
- 交互式长周期部署:小错误会累积,非确定性使复现困难
- 安全压力上升:提示注入、不受信任的检索内容、有副作用的工具需要纵深防御
核心框架:Agent Transformer
形式化定义
论文提出了 Agent Transformer 的统一抽象,将 Agent 系统形式化为一个五元组:
\[\mathcal{A} = (\pi_\theta, \mathcal{M}, \mathcal{T}, \mathcal{V}, \mathcal{E})\]其中:
- $\pi_\theta$:Transformer 策略模型(LLM/VLM)
- $\mathcal{M}$:记忆子系统(检索、摘要、状态)
- $\mathcal{T}$:工具集(API、代码执行、搜索、数据库)
- $\mathcal{V}$:验证器/批评器
- $\mathcal{E}$:环境
执行循环
在每一步 $t$,Agent 执行以下循环:
- 观察:从环境收集 $o_t \leftarrow \mathrm{Obs}(\mathcal{E}_t)$
- 检索:从记忆获取相关信息 $m_t \leftarrow \mathrm{Retrieve}(\mathcal{M}_t, o_t)$
- 提议:策略生成候选动作 $\tilde{a}t \sim \pi\theta(\cdot \mid o_t, m_t)$
- 验证:验证器检查动作 $\hat{a}_t \leftarrow \mathrm{Validate}(\mathcal{V}, \tilde{a}_t)$
- 执行:执行工具调用并更新状态
\(\mathcal{E}_{t+1} \leftarrow \mathrm{Exec}(\mathcal{E}_t, \mathcal{T}, \hat{a}_t)\) \(\mathcal{M}_{t+1} \leftarrow \mathrm{Update}(\mathcal{M}_t, o_t, \hat{a}_t, \mathcal{E}_{t+1})\)
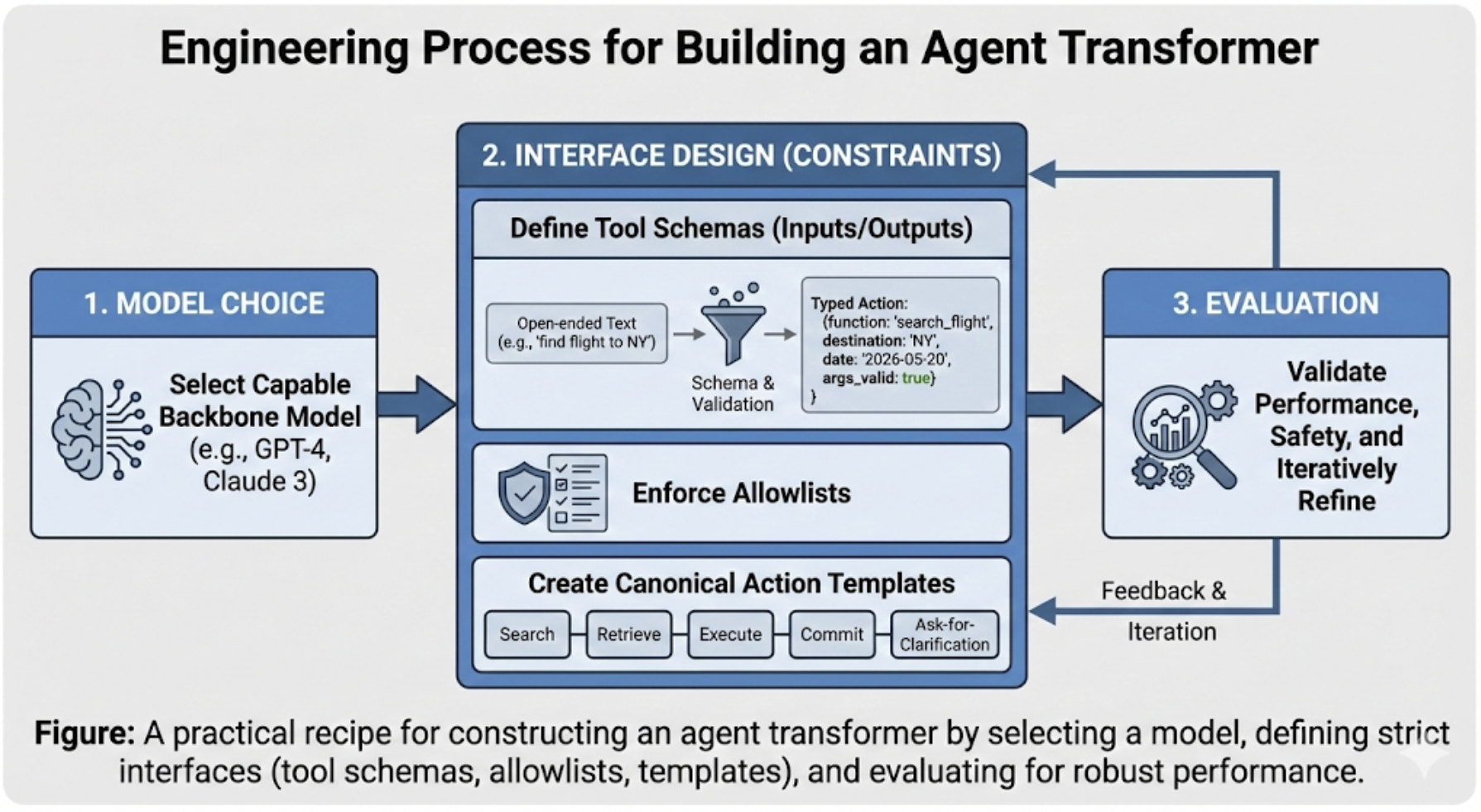 图 1:Agent Transformer 抽象,展示与记忆、工具、验证器和环境的显式接口
图 1:Agent Transformer 抽象,展示与记忆、工具、验证器和环境的显式接口
关键洞察:风险感知的预算控制器
最新范式将 Agent 循环视为风险感知、预算约束的控制器:
| 风险级别 | 示例 | 处理策略 |
|---|---|---|
| 低风险 | 只读查询、信息检索 | 最小化思考,快速执行 |
| 中风险 | 代码生成、内容创建 | 额外验证、自我一致性检查 |
| 高风险 | 写入数据库、部署、支付 | 多重验证、人类确认、沙箱执行 |
这一视角下,验证器不是可选附件,而是定义 Agent 操作语义的核心组件。
学习策略
1. 强化学习(RL)
RL 直接优化长周期回报,天然适合 Agent 行为学习:
优势:
- 优化行为而非单步预测
- 学习何时收集信息、何时行动、如何从错误中恢复
挑战:
- 稀疏/延迟奖励
- 昂贵的 rollout(工具调用成本高)
- 安全约束限制探索
实践建议:在工具丰富的环境中,优先使用离线 RL和约束 RL,从日志轨迹中优化而非在线探索。
2. 模仿学习(IL)
当专家演示可用时,IL 提供了一条实用路径:
关键形式:
- 行为克隆:直接匹配专家动作,适合工具调用(结构化参数 + 模式验证)
- DAgger:迭代收集纠正演示,提高分布外鲁棒性
- 逆 RL/GAIL:从专家轨迹推断隐式目标
实践建议:IL 训练的 Agent 需配合验证 - 修复循环(批评器、自校正、约束执行)处理分布外情况。
3. 上下文学习(In-Context Learning)
通过提示和示例实现快速任务适应,无需参数更新:
关键使能:
- 思维链提示:改进多步推理和分解
- ReAct 提示:将推理与工具使用绑定,提高可解释性
- 自一致性:聚合多条推理路径,提高稳定性
系统级失败模式:
- 上下文增长增加成本/延迟
- 长提示稀释关键约束
- 检索文本可能引入提示注入攻击
实践建议:上下文学习需与记忆(摘要、持久状态)、受信任检索和严格工具接口配合使用。
4. 系统级优化
Agent 性能是系统优化问题,而非单纯的建模问题:
| 优化维度 | 策略 | 权衡 |
|---|---|---|
| 搜索规划 | 探索替代动作序列 | 提高可靠性 vs. 增加计算 |
| 验证循环 | 检查动作并修订计划 | 降低失败率 vs. 增加延迟 |
| 缓存压缩 | 缓存检索、摘要记忆 | 控制上下文增长 vs. 信息损失 |
最佳实践:采用自适应优化——常规情况快速执行,高风险动作慢速验证路径,显式预算(时间、token、工具调用)和权限门控。
应用领域
1. 自主编码与软件维护
挑战:
- 长周期、工具丰富的任务(搜索代码库、多文件修改、运行测试)
- 理解隐式需求、依赖约束、跨模块耦合
- 工具链是移动目标(编译器、依赖解析器演化)
解决方案模式:
1
检索上下文 → 构建可执行计划 → 小步实现 → 运行测试/检查 → 迭代修复
关键设计:
- 将工具链作为一等公民(捕获命令和输出、总结失败)
- 结构化接口(文件编辑边界、补丁预览、测试选择策略)
- 执行前的轻量级审查/批评步骤
2. 企业工作流 Agent(CRM、IT、运维)
挑战:
- 严格的访问控制、审计、策略合规
- 分布式数据和权限(不同模式、身份、速率限制)
- 不受信任的输入(邮件、工单、附件)可能包含提示注入
解决方案模式:
- 编排式(多 Agent)设计:路由到专用工具、模式/白名单执行权限
- 策略即代码门控:谁可以在什么条件下做什么
- 强制人类确认:高影响变更
- 不可变审计日志:工具调用和检索证据
3. 浏览器与 GUI 操作 Agent
挑战:
- 部分可观察、动态布局、对抗性表面
- A/B 测试、本地化、响应式设计、弹窗、CAPTCHA
- 长周期任务放大累积错误
解决方案模式:
- ReAct 循环:推理与具体动作和检查交错
- 恢复策略:回溯、替代功能、重新解析屏幕
- 标准化环境:在真实变异性下报告鲁棒性和失败模式
4. 实时多模态助手(摄像头、屏幕、音频)
挑战:
- 延迟、上下文管理、接地
- 流式同步问题(音频 vs. 帧 vs. 屏幕状态)
- 隐私约束限制日志和调试
解决方案模式:
- 将感知分解为工具(OCR、检测、检索)
- LLM 作为编排器,管理中间产物记忆
- 结构化管道产生可检查的中间输出
5. 游戏领域
NPC 行为:
- 挑战:响应式、长周期一致性、游戏设计约束
- 方案:高层认知(LLM)+ 低层控制(小型策略/控制器)
人机交互:
- 挑战:接地于传说和当前世界状态、对抗性提示
- 方案:指令微调 LLM + 嵌入检索 + 显式记忆(情节摘要、关系状态)
游戏分析:
- 挑战:遥测噪声、因果归因困难、工具脆弱性
- 方案:LLM 总结 + 经典模型 + ReAct 绑定声明到执行的查询
6. 机器人
挑战:
- 部分观察、随机性、感知错误级联
- 实时控制严格时序约束
- 安全要求禁止开放探索
解决方案模式:
- 分层编排:高层规划器(语言→技能计划)+ 专用控制器(约束下执行)
- 工具调用接口:映射/SLAM、抓取/运动规划器、模拟 rollout
- 验证和重规划循环:从新传感器观察更新信念
7. 医疗健康
挑战:
- 安全/隐私关键、访问控制、数据驻留、审计要求
- 临床环境高风险、异构、分布偏移
- 信息碎片化、噪声、地面真实延迟/模糊
解决方案模式:
- 多模型组合:ASR(环境文档)、LLM(总结/草稿)、检索(指南/政策)
- 约束工作流 Agent:嵌入 EHR 相邻工具
- 工具调用严格限制:只读访问、模板化动作、最小权限范围
评测方法
核心指标
论文提出了系统的评测框架,涵盖多个互补维度:
1. 端到端任务性能(主要)
- 任务成功率:是否正确完成,达到预期终端状态
- 得分/奖励:环境提供的分级评分
2. 效率与成本
- 延迟:$t_i$( wall-clock 时间)
- Token 效率:输入/输出 token 计数
- 工具调用成本:$K_i$ 次调用,执行成功率
3. 鲁棒性与安全性
- 变异性鲁棒性:环境/工具变化下的性能
- 安全违规率:策略违反次数
- 提示注入抵抗:对抗性输入下的行为
4. 可复现性
- 轨迹完整性:提示、工具调用、中间状态日志
- 非确定性影响:采样/工具变异性的敏感度
评测实践建议
| 维度 | 推荐做法 |
|---|---|
| 基准选择 | 使用真实工具使用和长周期任务(WebArena、SWE-bench、ToolBench、AgentBench) |
| 报告指标 | 不仅成功率,还包括成本/延迟、轨迹完整性、鲁棒性、安全违规 |
| 消融实验 | 固定检索策略,报告上下文预算和规划器深度的影响 |
| 复现性 | 控制工具版本和参数,记录完整轨迹 |
开放挑战
1. 验证与护栏
- 如何为工具动作设计可验证的接口?
- 如何在自主性增加时限制错误影响范围?
- 如何平衡保守策略(过度拒绝)与不安全合规?
2. 可扩展的记忆与上下文管理
- 如何设计分层记忆(工作记忆 vs. 长期状态)?
- 如何在上下文增长时保持关键约束不被稀释?
- 如何处理检索到的提示注入和冲突信息?
3. 可解释性与审计
- 如何使 Agent 决策过程可追溯、可审计?
- 如何在隐私约束下实现充分的日志记录?
- 如何设计标准化的轨迹格式用于调试和复现?
4. 复现性评测
- 如何在真实工作负载下实现可复现的评测?
- 如何分离模型性能与系统优化(缓存、批处理、路由)的影响?
- 如何报告非确定性和工具变异性下的鲁棒性?
实践建议
基于综述内容,为 Agent 系统设计提供以下建议:
架构设计
- 采用 Agent Transformer 抽象:明确分离策略、记忆、工具、验证器、环境接口
- 实现风险感知控制器:根据动作可逆性调整验证深度
- 结构化动作空间:类型化工具模式 + 自动参数验证
学习策略
- 优先模仿学习:当高质量轨迹可用时,避免昂贵的在线探索
- 配合验证循环:IL 训练的 Agent 需批评器/自校正处理分布外情况
- 自适应优化:常规情况快速路径,高风险动作慢速验证路径
工具与记忆
- 工具作为一等公民:稳定模式、版本控制、审计日志
- 分层记忆设计:工作记忆(短期)+ 持久状态(长期)+ 程序记忆(技能)
- 检索接地:受信任源、模式验证、提示注入防护
安全与部署
- 纵深防御:检索、工具输出、动作门控的全链路检查
- 策略即代码:将合规要求编码为可执行门控
- 轨迹完整性:完整记录提示、工具调用、中间状态用于审计
总结
本综述提供了 AI Agent 系统的全面技术地图:
核心贡献:
- Agent Transformer 抽象:统一的形式化框架,明确组件接口
- 学习策略全景:RL、IL、上下文学习、系统优化的权衡与配合
- 应用领域洞察:7 大领域的挑战、解决方案模式、最佳实践
- 评测框架:多维度指标、复现性实践、开放挑战
关键洞察:
- Agent 性能是系统共设计问题,而非单纯模型问题
- 验证器定义操作语义,不是可选附件
- 风险感知控制器范式指导自主性与安全性的平衡
- 轨迹完整性是复现性、审计、持续改进的基础
对于从业者,建议从单 Agent + 结构化模式 + 验证循环开始,逐步增加复杂性和自主性,同时保持充分的审计和回滚能力。
参考链接
- 论文原文:arXiv 2601.01743