AgentArch 基准评测:企业工作流中的智能体架构选择指南
论文信息
- 标题: AgentArch: A Benchmark for Evaluating Agent Architectures in Enterprise Workflows
- 作者: Tara Bogavelli, Hari Subramani, Roshnee Sharma (ServiceNow)
- 发布: 2025
- GitHub: ServiceNow/AgentArch
- arXiv: 2509.10769
一句话总结
本文提出了 AgentArch——首个系统性评测企业工作流中智能体架构的基准,通过 18 种架构配置 × 6 个大模型的全面实验,揭示了模型特定的架构偏好,挑战了”一刀切”的智能体设计假设。
背景与动机
大语言模型已从简单的文本生成演变为能够自主决策、完成复杂任务的智能体。然而,企业从业者在构建智能体系统时面临两个关键缺口:
现有研究的局限性:
- 大多数工作孤立地评估单个组件(如编排策略、提示方法、记忆管理),缺乏对真实多智能体系统中架构交互的系统性研究
- 现有基准涵盖游戏、研究等多样领域,但极少专注于企业工作流场景
企业场景的特殊性:
- 需要高可靠性和与现有业务系统的无缝集成
- 工作流程步骤必须按预定义顺序执行
- 数据通常是复杂、冗长且混乱的,而非简化干净的基准数据
AgentArch 通过评估 18 种不同的智能体架构配置,跨越 6 个最先进的大语言模型,在两个真实企业用例上进行测试,填补了这一空白。
核心方法
评测维度
AgentArch 系统性地考察四个关键架构维度的交互:
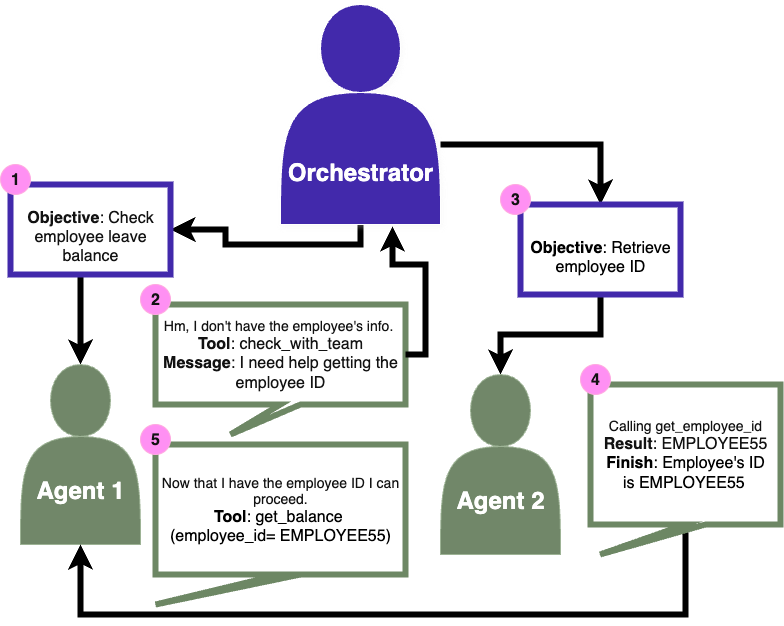
1. 编排策略(3 种)
- Orch-Open(开放网络):编排器分配初始任务,智能体之间直接通信
- Orch-Isolated(隔离智能体):编排器控制所有智能体间通信,智能体通过编排器请求帮助
- Single Agent(单智能体):单一智能体访问所有工具,无协作机制
2. 智能体风格(2 种)
- Function Calling:模型直接从工具包中选择工具,利用内置函数调用能力
- ReAct:模型输出显式推理后再选择动作,遵循结构化推理 - 行动框架
3. 记忆架构(2 种)
- Complete Memory:智能体看到所有先前的工具调用、参数和响应
- Summarized Memory:智能体仅接收先前智能体的最终摘要
4. 思考工具(2 种)
- Enabled:提供数学计算和信息综合工具
- Disabled:不提供显式推理辅助工具
组合总计:$3 \times 2 \times 2 \times 2 = 24$ 种,但部分组合不可行,实际评估 18 种配置。
企业用例
用例 1:请假申请(TO - Time Off)
- 复杂度:简单工作流
- 任务:PTO 资格验证和请求处理
- 工具数:8 个自定义工具
- 智能体数:3 个
- 关键挑战:日期计算、假期余额验证、政策合规性
用例 2:客户请求路由(CR - Customer Request)
- 复杂度:复杂工作流
- 任务:智能客服系统,自动处理简单请求,升级复杂问题
- 工具数:31 个自定义工具
- 智能体数:9 个
- 关键挑战:适当升级决策、上下文保留、处理模糊请求
每个用例包含 60 个用户请求,覆盖真实场景、边缘情况和失败条件。
评测模型
实验跨越 6 个主流大模型:
- GPT-4.1
- GPT-4o
- GPT-4.1-mini
- o3-mini
- LLaMA 3.3 70B
- Sonnet 4
实验结果
主要发现
1. 模型特定的架构偏好
实验结果强烈挑战了”通用最优设计”的假设。不同模型在不同架构配置下表现差异显著:
| 模型 | TO 最佳配置 | CR 最佳配置 |
|---|---|---|
| GPT-4.1 | Single Agent + Function Calling | Single Agent + Function Calling |
| Sonnet 4 | Single Agent + Function Calling | Single Agent + Function Calling |
| o3-mini | Single Agent + Function Calling | Orch-Isolated + Function Calling |
2. 性能差距显著
即使在最佳配置下,模型在企业任务上的表现仍有明显不足:
- 复杂任务(CR):最佳模型仅达到 35.3% 成功率
- 简单任务(TO):最佳模型达到 70.8% 成功率
这表明当前大模型在企业级应用中的可靠性仍有很大提升空间。
3. ReAct 在多智能体系统中的弱点
实验观察到一个有趣现象:ReAct 提示在多智能体系统中表现普遍较差。多数模型在 ReAct + 多智能体配置下成功率接近 0%。这可能是因为:
- 多轮通信中显式推理累积误差
- 智能体间协调增加了推理链复杂度
- 工具调用格式在传递过程中易出错
4. 大模型的架构鲁棒性
大模型(如 GPT-4.1、Sonnet 4)在不同架构间表现更稳定,而小模型(如 LLaMA 70B)对架构选择更敏感:
| 模型 | TO 均值 | TO 标准差 | 变异系数 |
|---|---|---|---|
| GPT-4.1 | 48.2 | 13.0 | 27.0 |
| Sonnet 4 | 49.0 | 15.7 | 32.1 |
| LLaMA 70B | 1.1 | 3.1 | 286.8 |
变异系数(CV)越低表示跨架构表现越稳定。
5. 简单任务中小模型可匹敌
在简单任务(TO)上,小模型在最佳配置下可达到与大模型相当的性能。但在复杂任务(CR)上,大模型优势明显。
模型一致性分析
下表展示了各模型在所有 18 种架构配置下的表现稳定性:
| 模型 | TO 均值 | TO 标准差 | TO 变异系数 | CR 均值 | CR 标准差 | CR 变异系数 |
|---|---|---|---|---|---|---|
| GPT-4.1 | 48.2 | 13.0 | 27.0 | 16.1 | 5.5 | 34.4 |
| GPT-4o | 31.4 | 18.7 | 59.7 | 1.8 | 1.5 | 83.9 |
| GPT-4.1-mini | 38.8 | 22.2 | 57.2 | 1.3 | 1.5 | 110.7 |
| o3-mini | 15.5 | 22.3 | 143.7 | 9.7 | 10.1 | 104.0 |
| LLaMA 70B | 1.1 | 3.1 | 286.8 | 0.0 | 0.0 | 0.0 |
| Sonnet 4 | 49.0 | 15.7 | 32.1 | 15.5 | 12.3 | 79.1 |
关键观察:
- GPT-4.1 和 Sonnet 4 在简单任务上表现稳定(CV < 35)
- 所有模型在复杂任务上的变异系数都显著增加
- LLaMA 70B 在两个任务上都表现不佳,几乎无法完成企业工作流
AI 分析方法亮点
问题定位精准
AgentArch 直接针对企业智能体系统的核心痛点:缺乏架构选择的实证指导。现有研究要么关注单一组件,要么使用简化基准,而本文通过真实企业数据(复杂 JSON 响应、冗长知识库文章)模拟生产环境挑战。
方法创新
- 首个系统性企业智能体基准:18 种架构配置 × 6 模型 × 2 用例,总计 216 个实验设置
- 四维联合分析:同时考察编排、提示风格、记忆设计、推理工具的交互效应
- 企业真实数据:故意构造复杂、混乱的数据,而非学术基准的干净响应
实用性强
实验结果直接指导工程实践:
- 简单任务:小模型在最佳配置下可匹敌大模型,可节省成本
- 复杂任务:必须选择大模型(GPT-4.1/Sonnet 4),且优先使用 Function Calling + 单智能体
- 避免陷阱:多智能体 + ReAct 组合在多数模型上表现极差,应避免使用
实践建议
基于实验结果,为企业智能体系统设计提供以下建议:
1. 模型选择
- 优先选择 GPT-4.1 或 Sonnet 4,两者在跨架构稳定性上表现最佳
- 避免使用 LLaMA 70B 处理企业工作流任务
2. 架构配置
- 简单任务:单智能体 + Function Calling + 完整记忆
- 复杂任务:单智能体 + Function Calling,谨慎使用多智能体
- 避免:ReAct + 多智能体组合(多数模型接近 0% 成功率)
3. 记忆策略
- 完整记忆通常优于摘要记忆,但代价是更长的上下文
- 对于长对话场景,可尝试摘要记忆以控制成本
4. 思考工具
- 对需要计算的任务(如日期计算、余额验证),启用思考工具有轻微提升
- 对分类/路由任务,思考工具影响不大
总结
AgentArch 通过大规模系统性实验,揭示了企业智能体架构设计的关键洞见:
- 不存在通用最优架构:模型特定偏好挑战了”一刀切”假设
- 企业任务极具挑战性:最佳模型在复杂任务上仅 35% 成功率
- ReAct 在多智能体中表现差:这是反直觉但重要的发现
- 大模型更鲁棒:跨架构表现稳定,适合生产部署
对于从业者,建议优先尝试 单智能体 + Function Calling 配置,这是目前工程实践最成熟的方案。同时,AgentArch 的代码和数据已开源,可作为企业智能体开发的参考基准。
参考链接
- 论文原文:arXiv 2509.10769
- 代码仓库:ServiceNow/AgentArch