SCOTT:自洽思维链蒸馏 - 让小型模型学会忠实推理
论文信息
- 标题: SCOTT: Self-Consistent Chain-of-Thought Distillation
- 作者: Peifeng Wang et al. (USC, Amazon)
- 会议: ACL 2023
- arXiv: 2305.01879
- 代码: GitHub
📊 本文插图
- Figure 1: GPT-3 生成的空洞推理示例
- Figure 2: SCOTT 知识蒸馏框架总览
- Figure 3: 对比解码方法
- Figure 4: 反事实推理训练
- Figure 5-8: 实验结果
一句话总结
这篇论文提出了 SCOTT,一种知识蒸馏方法,通过对比解码训练一致性教师、反事实推理训练忠实学生,让小型模型学会生成与答案一致的思维链推理过程。
背景与动机
思维链的局限性
大型语言模型通过思维链 (Chain-of-Thought, CoT) 提示展现出强大的推理能力。然而,CoT 存在两个严重问题:
- 规模依赖: 只有在足够大的模型上才能观察到性能提升
- 不忠实: 生成的推理过程与预测答案不一致,无法真正解释模型的决策
作者对 GPT-3 生成的 100 个推理样本进行分析,发现:
- 42% 的推理没有提供问题陈述之外的新信息
- 37% 的推理无法证明答案的合理性
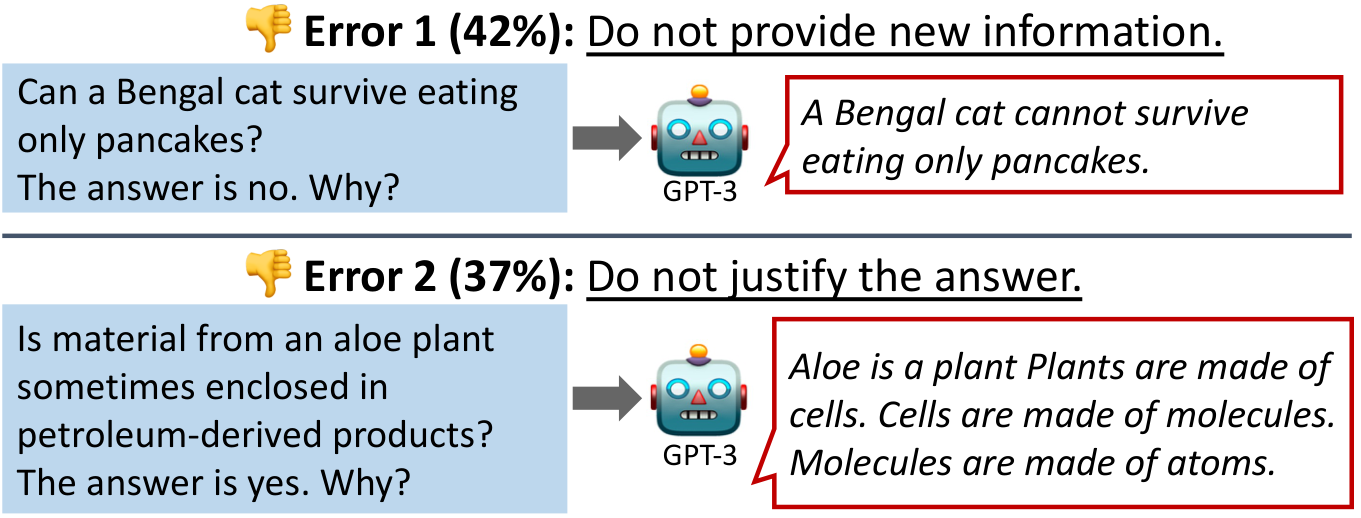 图 1:GPT-3 生成的空洞推理示例。两种错误情况都因幻觉导致推理与答案不一致
图 1:GPT-3 生成的空洞推理示例。两种错误情况都因幻觉导致推理与答案不一致
知识蒸馏的问题
现有工作尝试用大型教师模型训练小型学生模型,但存在两个问题:
- 教师幻觉: 教师模型生成的推理可能不支撑给定答案
- 学生走捷径: 学生学会利用问题与答案的虚假相关性,忽略生成的推理
这两个问题导致学生模型生成空洞推理,且预测与推理不一致。
核心方法
SCOTT 从两个端点改进传统的知识蒸馏框架:
整体框架
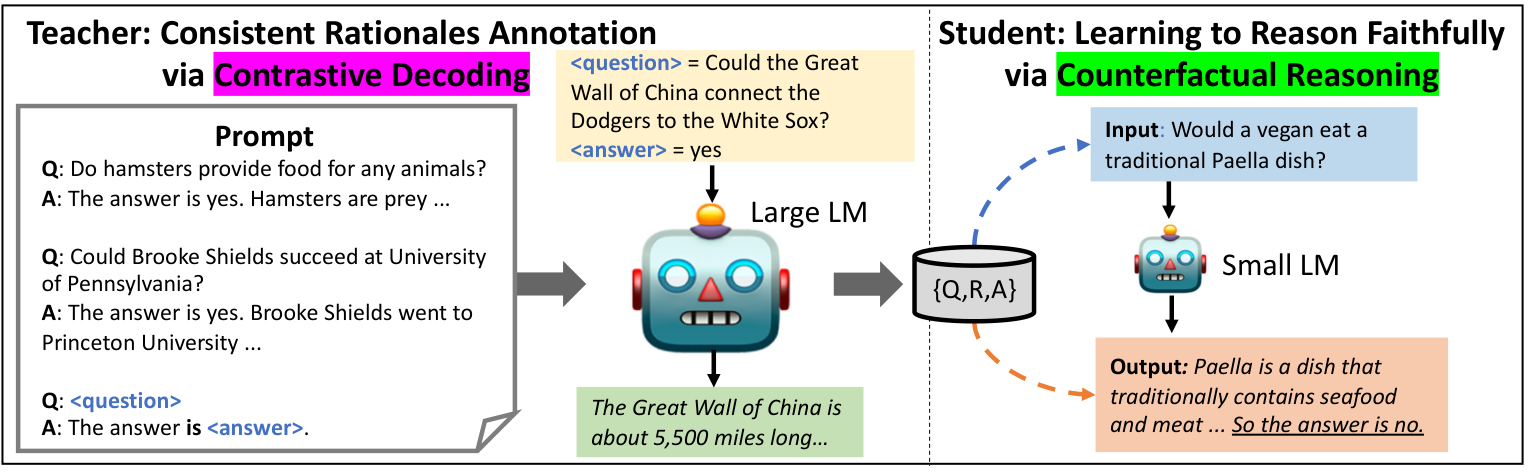 图 2:SCOTT 知识蒸馏框架概览。(a) 教师:通过对比解码从大型模型获取一致性推理;(b) 学生:通过反事实推理微调小型模型
图 2:SCOTT 知识蒸馏框架概览。(a) 教师:通过对比解码从大型模型获取一致性推理;(b) 学生:通过反事实推理微调小型模型
1. 一致性教师:对比解码
为了促使教师生成更切题的推理,作者提出对比解码 (Contrastive Decoding)。
核心思想: 偏好那些”只有在考虑答案时才更合理”的 token,而不是”即使不考虑答案也很合理”的 token。
实现方法:
- 用扰动答案(空字符串或错误答案)建模幻觉行为
- 计算 token 的可信度增长:
- 将可信度增长整合到解码策略中:
 图 3:对比解码示例。与贪婪解码相比,对比解码生成的推理更具体、更支撑答案
图 3:对比解码示例。与贪婪解码相比,对比解码生成的推理更具体、更支撑答案
两种扰动方式:
- 空字符串: 惩罚那些不考虑答案时也很通用的 token
- 错误答案: 进一步鼓励生成能区分正确/错误答案的推理
2. 忠实学生:反事实推理
为了让学生忠实于生成的推理,作者训练学生进行反事实推理 (Counterfactual Reasoning)。
核心思想: 当推理指向不同答案时,学生应相应地改变预测。这消除了问题与答案之间的推理捷径。
实现方法:
- 用错误答案替换教师输入中的正确答案,生成反事实推理
- 训练学生根据反事实推理预测错误答案:
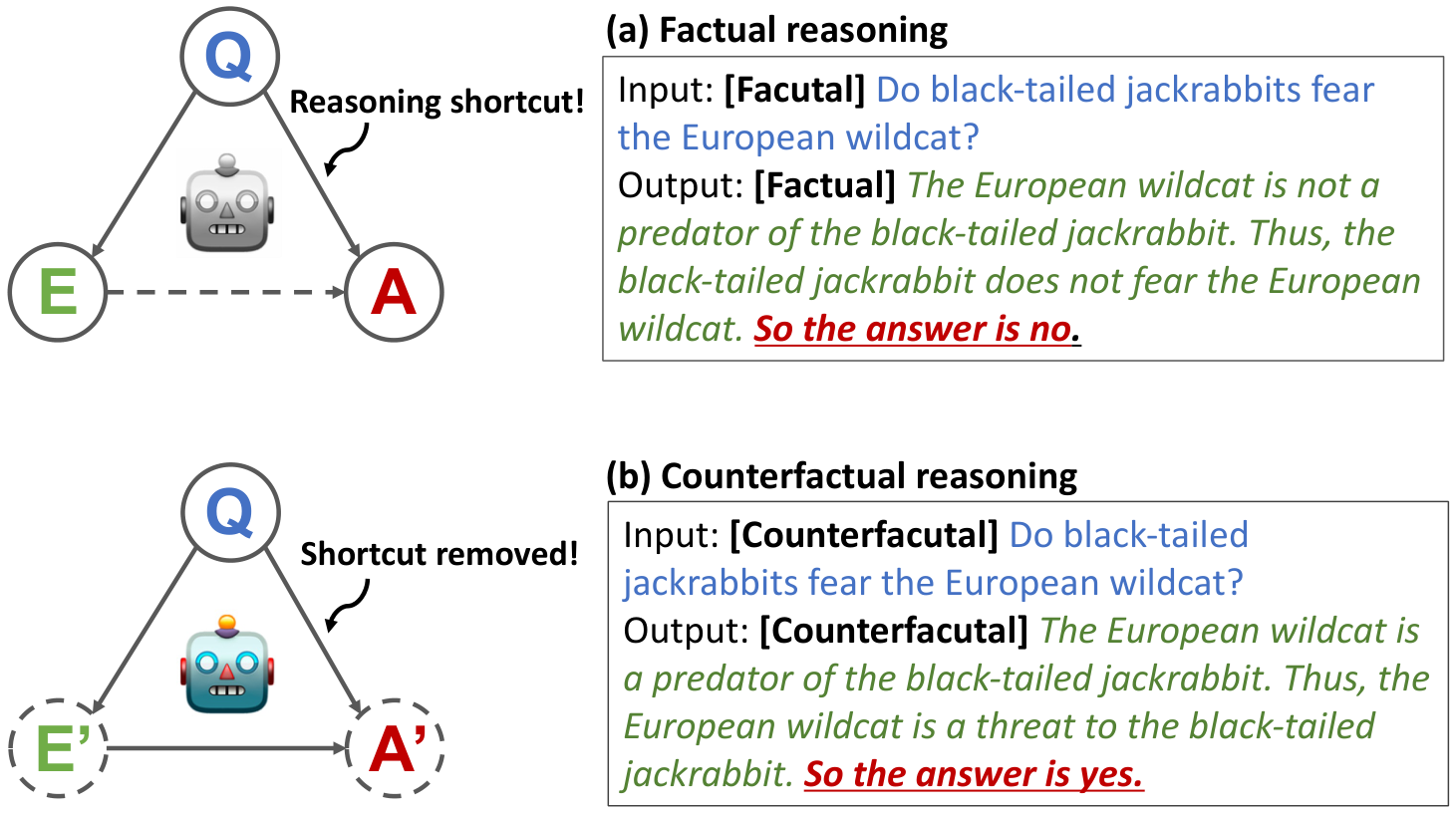 图 4:反事实推理训练。学生学会根据推理内容而非问题本身来预测答案
图 4:反事实推理训练。学生学会根据推理内容而非问题本身来预测答案
避免混淆: 在输入和输出开头添加 [Factual] 或 [Counterfactual] 关键词区分训练目标。
总损失: 事实推理损失 + 反事实推理损失
实验结果
数据集
- CSQA: 常识推理(5 选 1)
- StrategyQA: 隐含推理步骤的是非问答
- CREAK: 事实验证(真/假)
- QASC: 知识检索 + 组合推理(8 选 1)
评估指标
- 一致性 (LAS): 推理辅助模拟器预测教师答案的能力提升
- 忠实性 (LAS): 推理辅助模拟器预测学生答案的能力提升
- 任务性能: 准确率
主要结果
1. 对比解码能否训练更一致的教师?
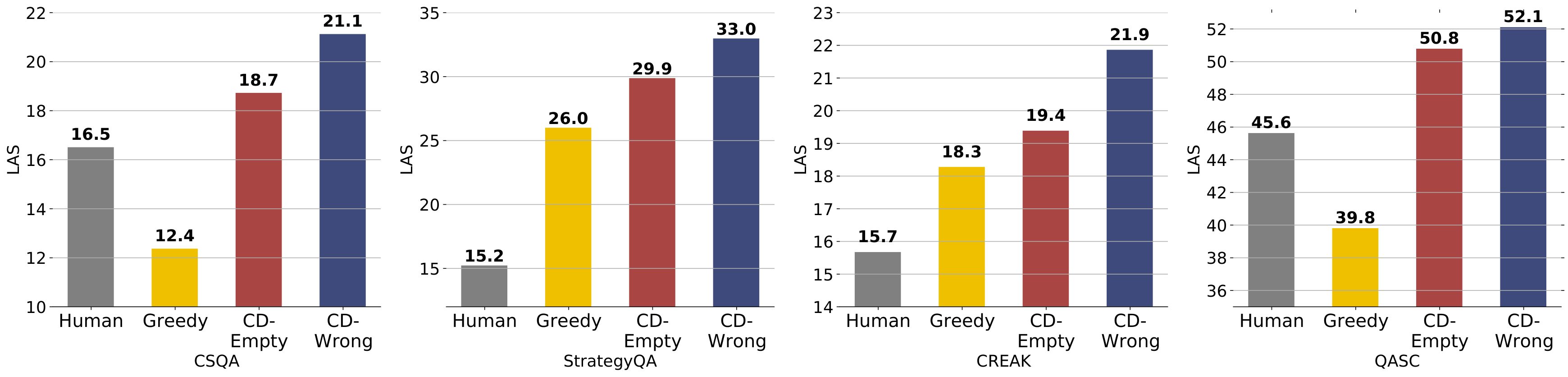 图 5:不同教师模型的一致性对比。CD-Empty/CD-Wrong 表示使用空字符串/错误答案的对比解码
图 5:不同教师模型的一致性对比。CD-Empty/CD-Wrong 表示使用空字符串/错误答案的对比解码
发现:
- 对比解码(无论空字符串还是错误答案)在 4 个数据集上都优于人类标注和贪婪解码
- 使用错误答案比空字符串效果更好(生成更具区分性的推理)
- 贪婪解码甚至不如人类标注(验证了 LLM 容易产生幻觉)
2. 更一致的教师能否训练更忠实的学生?
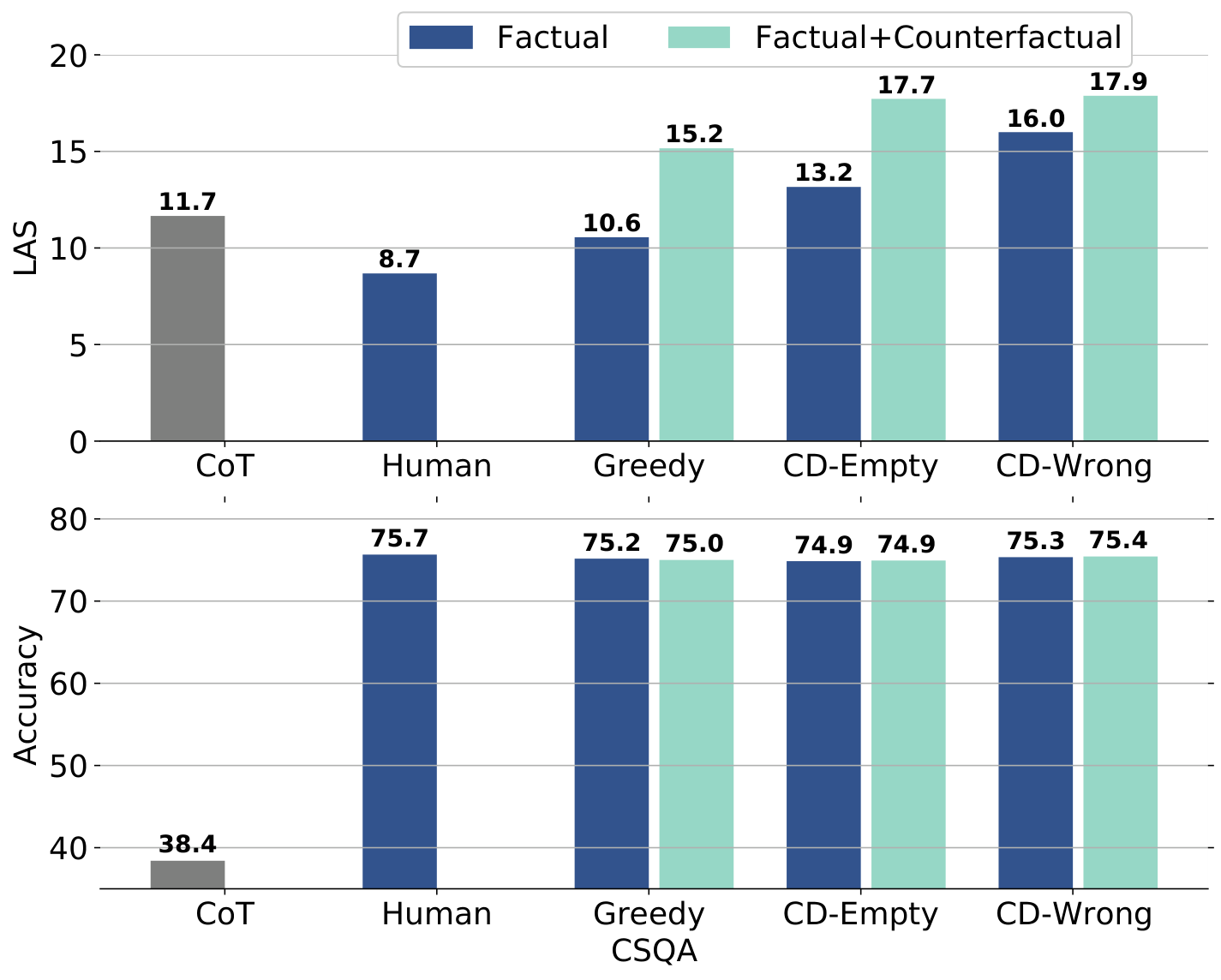 图 6:各方法的忠实性 (LAS) 和任务性能 (准确率) 对比(CSQA 数据集)
图 6:各方法的忠实性 (LAS) 和任务性能 (准确率) 对比(CSQA 数据集)
发现:
- CoT 方法的 LAS 远低于知识蒸馏方法(推理不忠实反映决策)
- 对比解码训练的学生忠实性更高
- 一致性会从教师继承到学生
3. 反事实推理能否进一步提升忠实性?
发现:
- 添加反事实训练损失的学生忠实性更高
- 学生不再将推理生成和答案预测视为独立过程
4. 忠实的学生能否保持性能?
发现:
- 所有知识蒸馏方法性能相当
- SCOTT 在提升忠实性的同时不牺牲准确率
学生模型规模消融
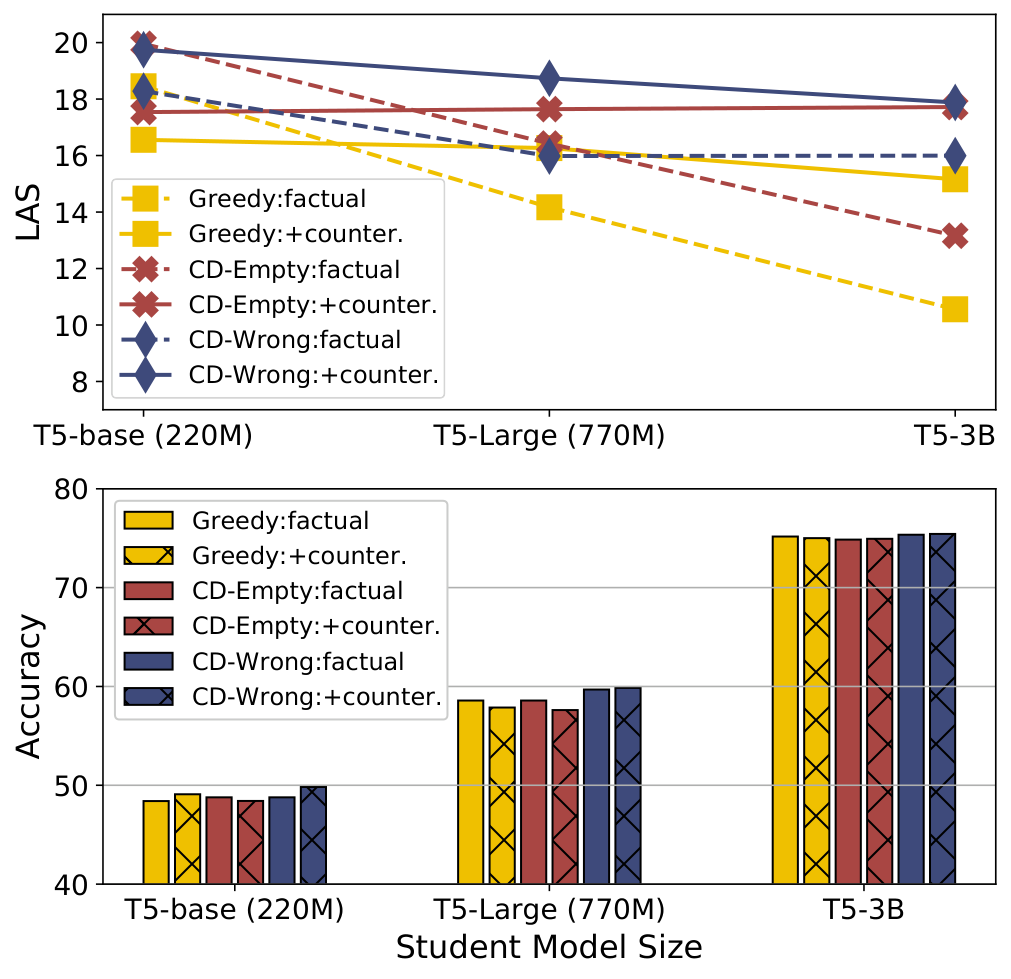 图 7:不同学生模型规模的忠实性与性能对比
图 7:不同学生模型规模的忠实性与性能对比
发现:
- 更大的模型性能更好但忠实性更低
- SCOTT 方法在不同规模下都稳健地提升忠实性
控制学生行为
通过修改学生的推理,能否控制其预测?
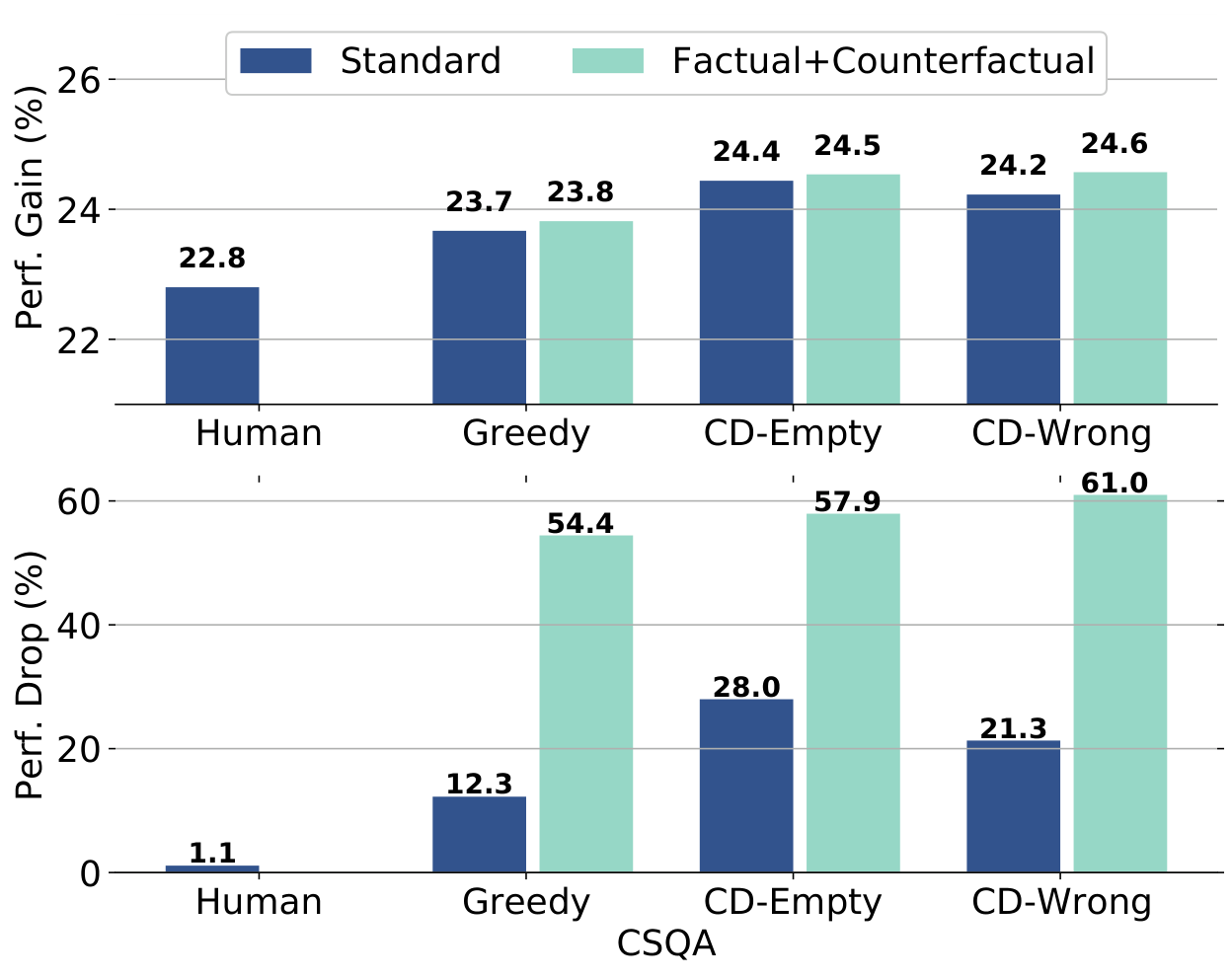 图 8:推理扰动/优化后的性能变化(CSQA)
图 8:推理扰动/优化后的性能变化(CSQA)
推理扰动(随机替换 50% token):
- 人类标注训练的学生性能几乎不受影响(忽略推理)
- SCOTT 训练的学生更敏感(忠实于推理)
推理优化(使用 Oracle 推理):
- SCOTT 训练的学生性能提升更大
- 可通过优化推理来调试模型
AI 分析方法亮点
问题定位精准: 直接针对 CoT 的”不忠实”核心问题——生成的推理过程与预测答案不一致,无法真正解释模型的决策
方法创新: 提出双端改进策略,通过对比解码训练一致性教师,通过反事实推理训练忠实学生,形成闭环优化
实用性强: 小型模型也能获得忠实推理能力,在保持性能的同时显著降低部署成本;可通过修改推理来调试模型,提供可解释性
总结
SCOTT 通过对比解码和反事实推理两个关键技术,成功训练出生成忠实推理的小型模型。实验表明,该方法在保持性能的同时显著提升了推理的忠实性,为可解释推理系统提供了新思路。
核心 takeaway: 一致性会从教师继承到学生,因此训练数据的質量至关重要。
参考链接
- 📄 论文原文
- 💻 代码仓库
- 📊 ACL Anthology