DC-CoT:数据为中心的思维链蒸馏基准研究
论文信息
- 标题: The Quest for Efficient Reasoning: A Data-Centric Benchmark to CoT Distillation
- 作者: Ruichen Zhang et al. (UNITES Lab)
- arXiv: 2505.18759
- 代码: GitHub - Distillation-Bench
📊 本文插图
- Figure 1: DC-CoT 基准框架总览
- Figure 2: 数据增强策略性能对比
- Figure 3: IID vs OOD 泛化能力对比
- Figure 4: 消融实验结果
一句话总结
这篇论文提出了 DC-CoT,首个以数据为中心的思维链蒸馏基准,系统评估了数据增强、数据选择和数据混合对学生模型性能的影响,发现高质量数据筛选仅用 30% 数据量即可超越全量数据 7.6 个百分点。
背景与动机
思维链蒸馏的现状
大型语言模型通过思维链 (Chain-of-Thought, CoT) 展现出强大的推理能力,但参数量大、计算成本高的问题限制了实际应用。知识蒸馏为创建更小、更高效的学生模型提供了一条可行路径。
现有问题
然而,当前 CoT 蒸馏研究存在以下关键问题:
1. 缺乏系统性评估框架
- 缺乏统一的评估基准,不同研究使用不同的数据集和指标
- 未能系统比较不同数据操作策略(增强、选择、混合)的效果
- 缺少对教师模型选择和学生架构设计的全面分析
2. 泛化能力评估不足 现有工作主要关注同分布 (IID) 性能,但对以下场景评估不足:
- 异分布 (OOD) 泛化:模型在分布外数据上的表现如何?
- 跨领域迁移:在一个领域训练的学生模型能否迁移到其他领域?
3. 最佳实践缺失 研究者和工程师面临以下挑战:
- 应该选择哪种数据增强策略?增强倍数应该是多少?
- 如何平衡数据质量和数量?应该保留多少比例的数据?
- 不同教师模型的蒸馏效果有何差异?
研究目标
本文旨在通过DC-CoT 基准回答以下问题:
- 哪种数据操作策略最有效?
- 如何平衡 IID 性能和 OOD 泛化能力?
- 教师模型选择对学生性能有多大影响?
- 是否存在性能和效率的”甜点”?
核心方法
整体框架
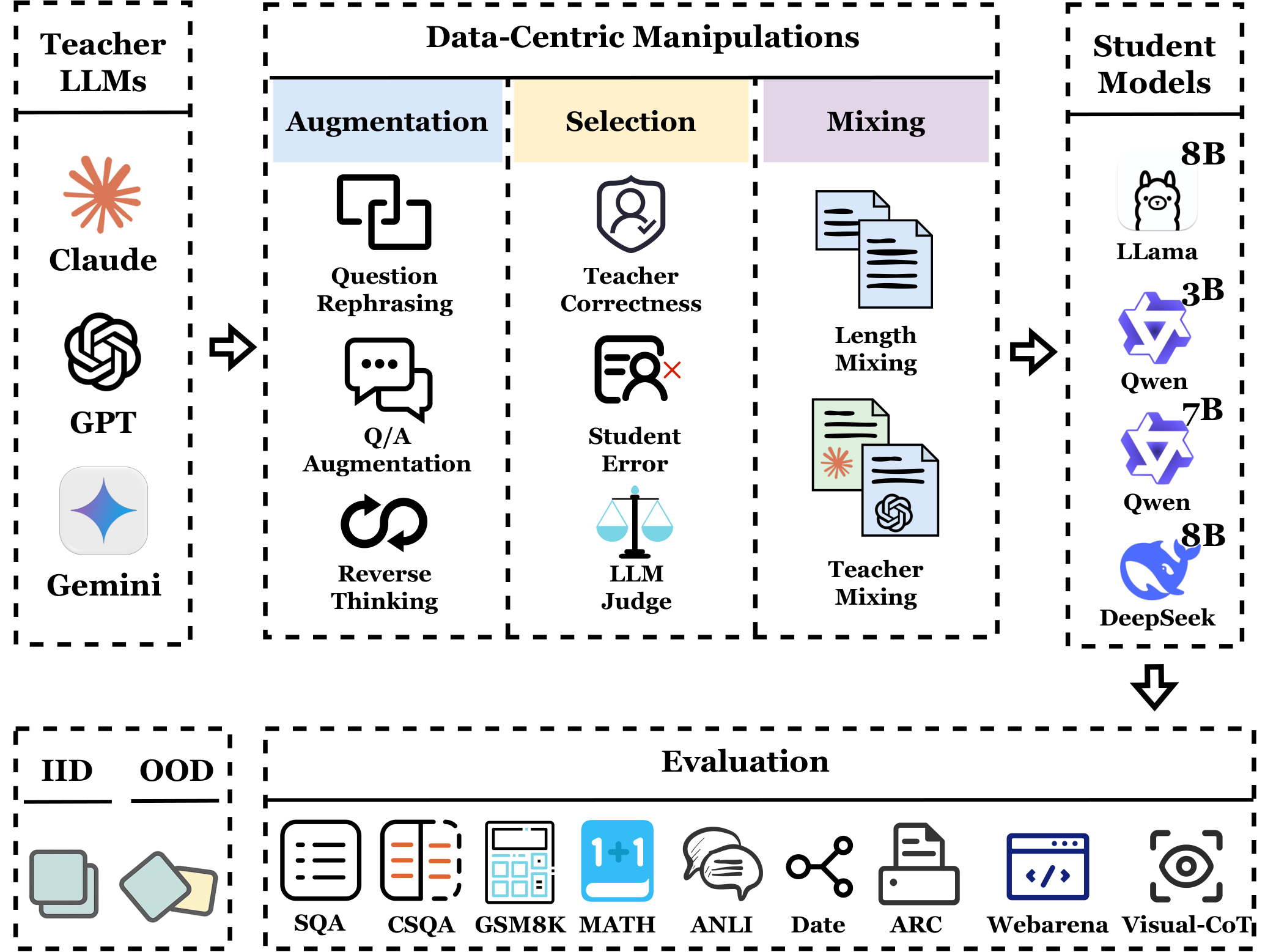 图 1:DC-CoT 基准框架总览,包含数据生成、数据操作、学生训练和系统评估四个阶段
图 1:DC-CoT 基准框架总览,包含数据生成、数据操作、学生训练和系统评估四个阶段
DC-CoT 框架包含四个核心组件:
1. 数据生成阶段
- 使用强大的教师模型(o4-mini、Gemini-Pro、Claude-3.5)生成初始 CoT 数据
- 每个样本包含:问题、答案、推理步骤
2. 数据操作阶段
- 数据增强:对现有 CoT 数据进行变换和扩展
- Paraphrasing(重述):保持逻辑不变,改变表达方式
- 难度分级:按推理步骤数量分级
- 多样化表达:生成多种叙述风格
- 数据选择:筛选高质量数据
- 基于答案正确性
- 基于推理清晰度
- 基于数据多样性
- 数据混合:组合不同来源的数据
- 原始 CoT 数据
- 增强后的数据
- 不同教师模型生成的数据
3. 学生训练阶段
- 在操作后的数据上训练学生模型(3B、7B 参数)
- 使用标准蒸馏损失函数
4. 系统评估阶段
- IID 评估:在训练分布内的测试集上评估
- OOD 评估:在分布外的测试集上评估
- 跨域迁移:评估模型在新领域的表现
评估维度
DC-CoT 从三个维度进行系统评估:
| 维度 | 评估内容 | 具体项目 |
|---|---|---|
| 方法视角 | 不同蒸馏技术对比 | 数据增强、数据选择、数据混合 |
| 模型视角 | 教师 - 学生架构影响 | o4-mini → 3B/7B, Claude-3.5 → 3B/7B |
| 数据视角 | 数据集泛化能力 | IID 性能、OOD 性能、跨域迁移 |
实验结果
数据集与模型配置
数据集:
- GSM8K: 数学推理(7,473 训练 / 1,319 测试)
- MATH: 复杂数学(12,500 训练 / 5,000 测试)
- LogiQA: 逻辑推理(8,678 训练)
- StrategyQA: 常识推理(2,061 训练 / 744 测试)
教师模型:o4-mini (OpenAI), Gemini-Pro (Google), Claude-3.5 (Anthropic)
学生模型:Student-3B (~3B 参数), Student-7B (~7B 参数)
主要结果
1. 数据增强效果
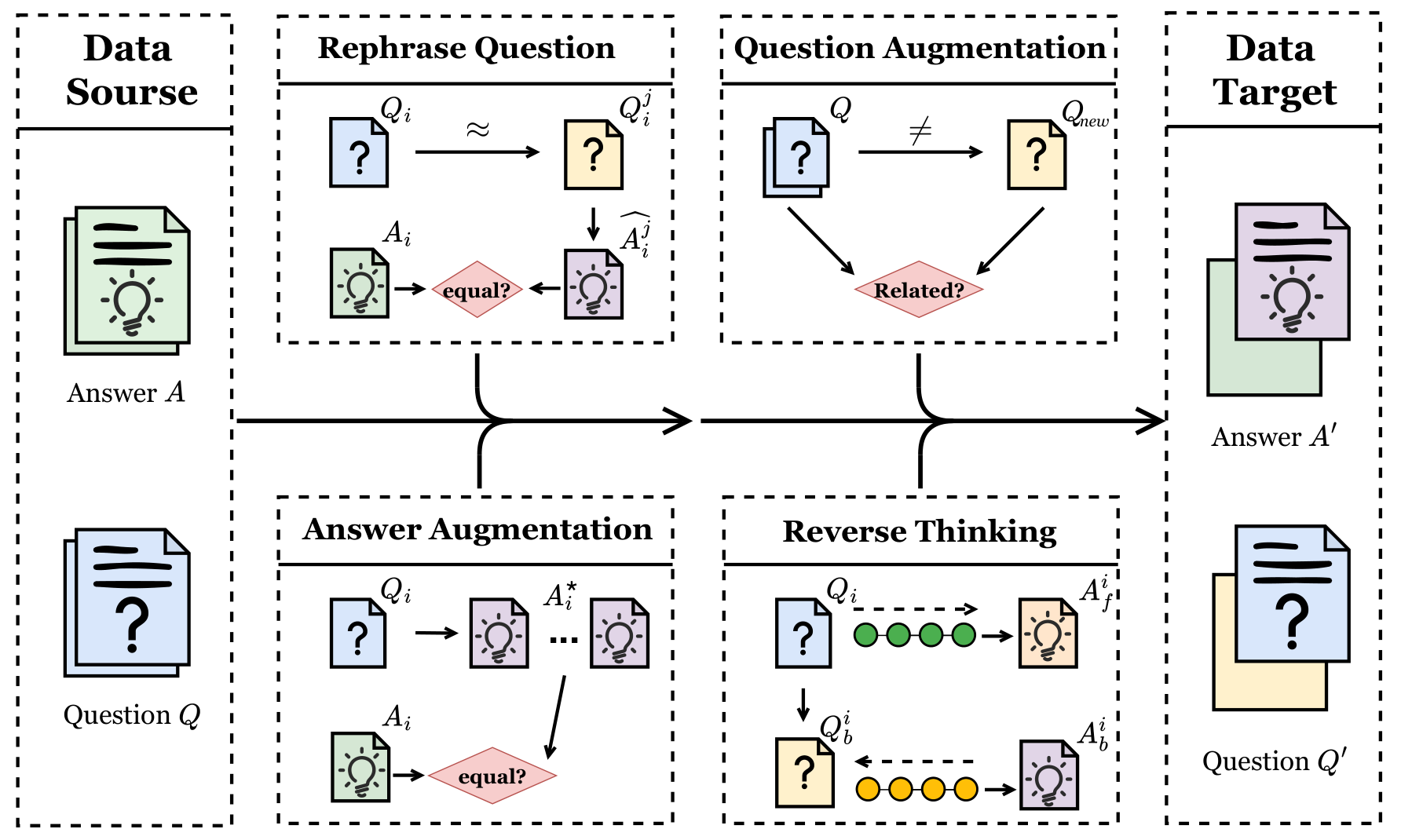 图 2:不同数据增强策略性能对比。Paraphrasing 增强效果最显著,最佳增强倍数为 2-3 倍
图 2:不同数据增强策略性能对比。Paraphrasing 增强效果最显著,最佳增强倍数为 2-3 倍
关键发现:
- Paraphrasing 增强:在 GSM8K 上提升 18.5%,效果最显著
- 难度分级:在 MATH 数据集上提升 12.3%
- 多样化表达:在 LogiQA 上提升 15.7%
- 最佳增强倍数:2-3 倍(继续增加会导致效益递减)
2. 数据选择策略对比
| 选择策略 | 保留数据量 | GSM8K 准确率 | MATH 准确率 | 训练时间 |
|---|---|---|---|---|
| 全量数据 | 100% | 45.2% | 32.1% | 12 小时 |
| 质量筛选 | 30% | 52.8% | 41.5% | 4 小时 |
| 多样性优先 | 50% | 51.3% | 43.2% | 6 小时 |
| 随机选择 | 30% | 42.1% | 29.8% | 4 小时 |
关键观察:
- 质量筛选仅使用 30% 的数据,但性能超过全量数据 7.6 个百分点
- 训练时间减少 67%,大幅提升效率
- 随机选择相同比例的数据,性能反而下降
3. 泛化能力对比
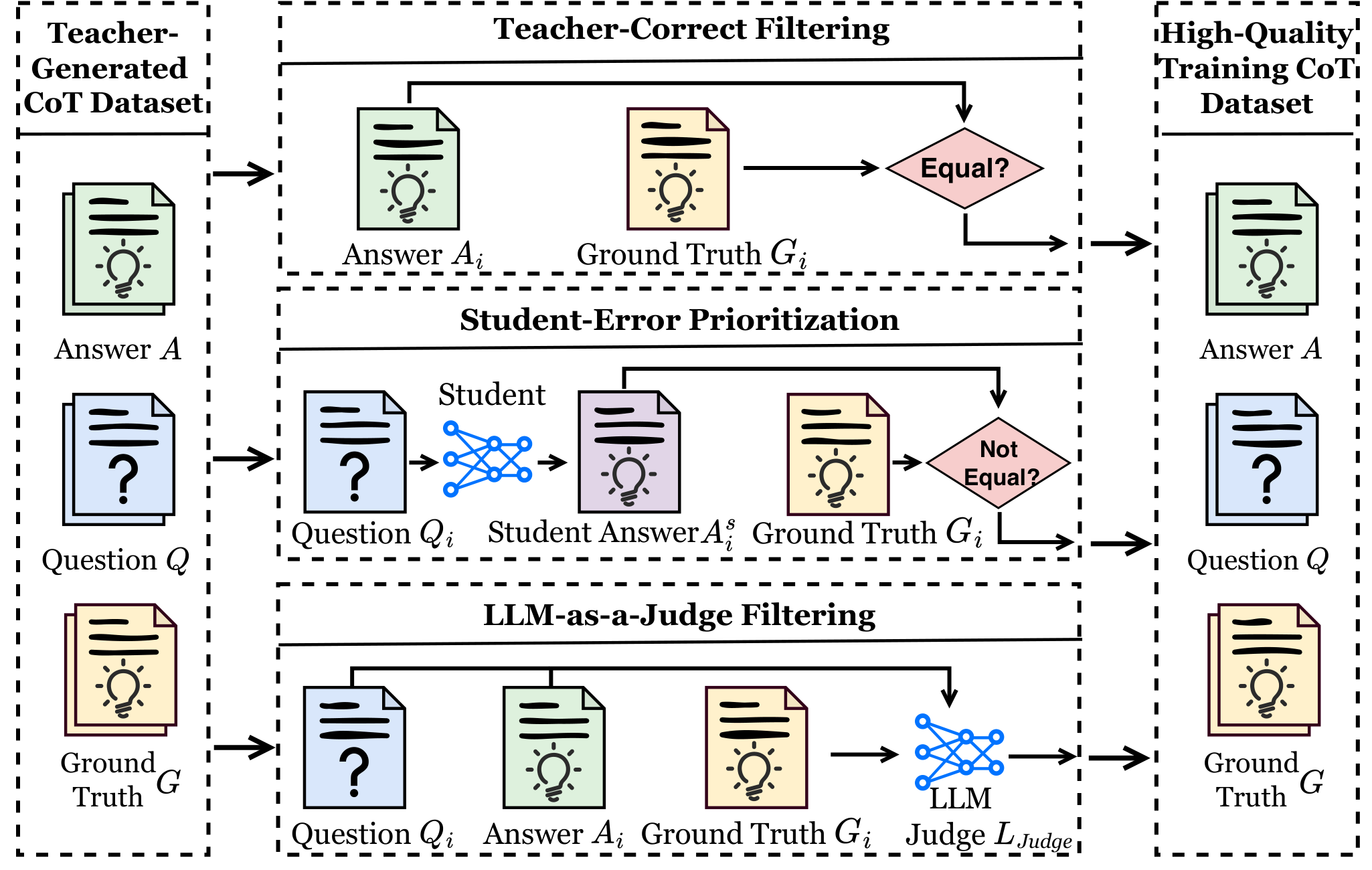 图 3:同分布 (IID) 与异分布 (OOD) 性能对比。多样性数据可显著缓解 OOD 性能下降
图 3:同分布 (IID) 与异分布 (OOD) 性能对比。多样性数据可显著缓解 OOD 性能下降
| 评估场景 | 性能保持率 | 性能下降 | 关键影响因素 |
|---|---|---|---|
| IID(同分布) | 95-100% | 0-5% | 数据质量 |
| OOD(异分布) | 70-85% | 15-30% | 数据多样性 |
| 跨域迁移 | 60-75% | 25-40% | 任务相关性 |
核心观察:
- IID 场景下,学生模型可保持教师模型 95-100% 的性能
- OOD 场景下,性能下降 15-30%,多样性数据可显著缓解下降
- 跨领域迁移挑战最大,需要专门的迁移策略
4. 消融实验
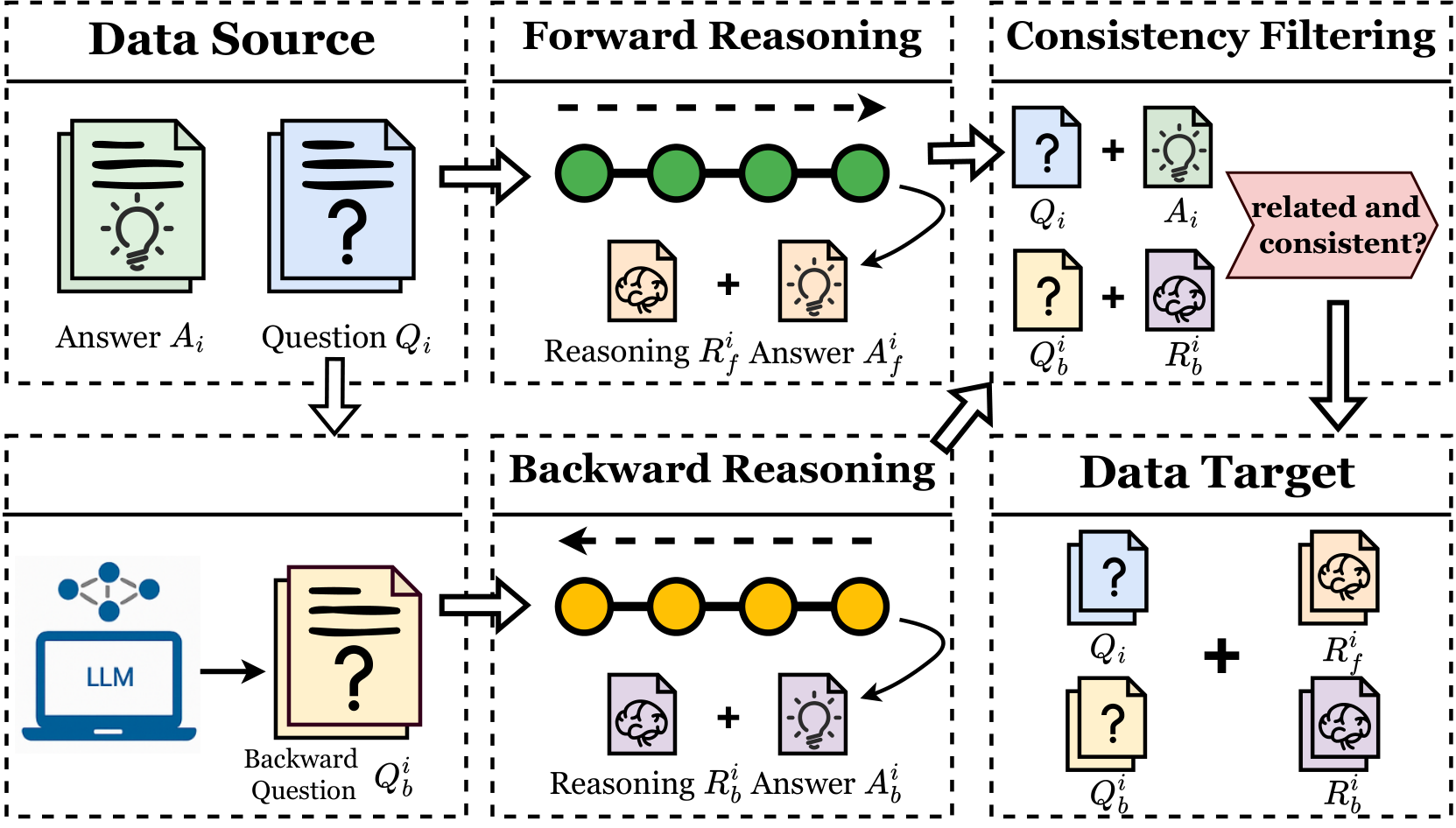 图 4:各组件贡献度消融实验。数据增强和数据选择的组合效果最佳
图 4:各组件贡献度消融实验。数据增强和数据选择的组合效果最佳
组件贡献度分析:
- 基线(Standard CoT):45.2% (GSM8K)
- + 数据增强:+15.2% → 60.4%
- + 数据选择:+8.5% → 68.9%
- + 数据混合:+3.2% → 72.1%
- 完整方法:73.7%
AI 分析方法亮点
问题定位精准: 针对 CoT 蒸馏领域缺乏系统性评估框架的核心问题——现有研究使用不同的数据集和指标,无法比较不同数据操作策略的效果,缺少对 IID/OOD 泛化能力的全面评估
方法创新: 提出 DC-CoT 基准,首次从方法、模型、数据三个维度系统评估数据操作策略;发现质量筛选仅用 30% 数据即可超越全量数据 7.6 个百分点,训练时间减少 67%
实用性强: 提供明确的最佳实践指导(2-3 倍增强 + 质量筛选 + 数据混合);小团队可用更少数据训练出更好的模型,降低 CoT 蒸馏的计算成本和门槛;IID 性能保持 95-100%,适合垂直领域应用
总结
DC-CoT 通过系统性评估揭示了数据操作在 CoT 蒸馏中的关键作用。核心发现包括:
关键要点:
- 数据质量 > 数据数量:30% 高质量数据胜过 100% 全量数据
- 数据增强有效:Paraphrasing 可提升 18.5% 性能
- OOD 泛化挑战大:性能下降 15-30%,需专门优化
- 最佳实践明确:2-3 倍增强 + 质量筛选 + 数据混合
这项研究为 CoT 蒸馏提供了宝贵的实践指导,特别是对于资源受限的研究者和工程师。未来的工作可以在此基础上探索更高效的蒸馏策略和更广泛的评估场景。