CoT-Self-Instruct:思维链引导的高质量数据合成方法
论文信息
- 标题: CoT-Self-Instruct: Building High-Quality Synthetic Data for Reasoning and Non-Reasoning Tasks
- 作者: Ping Yu et al. (FAIR at Meta, NYU)
- 会议: ICLR 2025
- arXiv: 2507.23751
📊 本文插图
- Figure 1: CoT-Self-Instruct 方法总览
一句话总结
这篇论文提出了 CoT-Self-Instruct,通过让 LLM 在生成合成数据前先进行思维链推理分析,再结合答案一致性过滤(推理任务)和 RIP 过滤(非推理任务),在 MATH500 等基准上超越现有数据集,仅用合成数据即可训练出超越人类数据标注的模型。
背景与动机
高质量数据稀缺问题
大型语言模型的发展依赖于大规模高质量数据。然而,获取人类标注数据面临以下挑战:
- 成本高昂: 专业领域(如数学推理)的标注需要专家知识
- 数据稀缺: 某些任务难以收集足够的真实数据
- 隐私问题: 敏感数据无法直接用于训练
- 人类偏差: 人类标注可能存在系统性偏差
现有方法的局限
Self-Instruct 等现有方法通过 LLM 自身生成合成数据,但存在关键问题:
- 缺乏规划: 直接生成指令,缺少对种子指令的深度分析
- 质量不稳定: 生成的数据复杂度和质量波动大
- 过滤机制弱: 简单的去重和聚类无法保证数据质量
研究目标
本文旨在回答以下问题:
- 如何让 LLM 生成更高质量的合成指令?
- 如何设计有效的过滤机制筛选优质数据?
- 合成数据能否在推理和非推理任务上都超越人类数据?
核心方法
整体框架
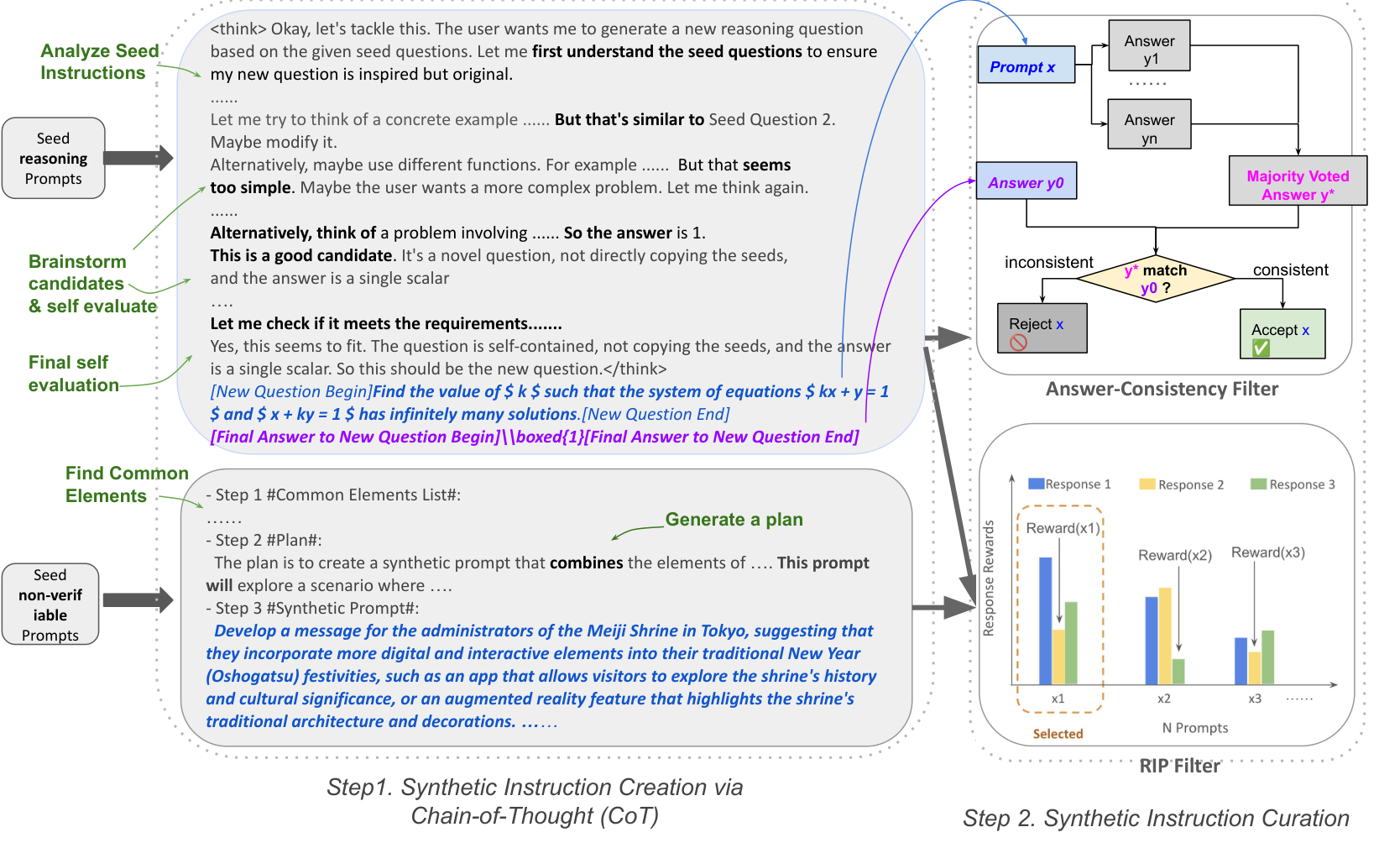 图 1:CoT-Self-Instruct 方法流程。LLM 先通过 CoT 分析种子指令并生成新指令,再通过 Answer-Consistency(推理任务)或 RIP(非推理任务)进行质量过滤
图 1:CoT-Self-Instruct 方法流程。LLM 先通过 CoT 分析种子指令并生成新指令,再通过 Answer-Consistency(推理任务)或 RIP(非推理任务)进行质量过滤
CoT-Self-Instruct 包含两个核心阶段:
1. 合成指令生成(带 CoT)
- 给定少量种子指令,让 LLM 先分析其属性(领域、复杂度、目的)
- 通过思维链推理,规划如何生成类似质量的新指令
- 最终输出自包含的合成指令
2. 指令质量过滤
- 推理任务: Answer-Consistency 过滤
- 非推理任务: RIP (Rejecting Instruction Preferences) 过滤
关键技术 1:CoT 指令生成
核心思想: 让 LLM 在生成指令前先”思考”,分析种子指令的特点并制定生成计划。
实现方法(推理任务):
LLM 需要同时生成指令和可验证答案,格式如下:
1
2
[New Question Begin]{生成的问题}[New Question End]
[Final Answer to New Question Begin]\boxed{最终答案}[Final Answer to New Question End]
关键要求:
- 答案必须是明确的标量值(整数、分数)或可单步验证的类型(是/否、A-D 选项)
- 问题必须自包含,不依赖外部信息
实现方法(非推理任务):
对于开放式任务(写作、编程等),LLM 仅生成指令,不提供参考答案。后续通过奖励模型评估响应质量。
关键技术 2:质量过滤
Answer-Consistency(推理任务)
核心思想: 如果 LLM 多次生成的答案与 CoT 生成的目标答案不一致,说明该指令可能质量低或过于困难。
实现步骤:
- 对生成的指令,让 LLM 生成 K 个响应(通常 K=16)
- 对最终答案进行多数投票
- 如果多数投票答案 ≠ CoT 生成的目标答案,则丢弃该指令
优势: CoT 生成的答案包含详细的推理过程,比推理时生成的答案更可靠,提供了额外的质量保障。
RIP 过滤(非推理任务)
核心思想: 基于奖励模型对 LLM 响应的评分分布来过滤低质量指令。
实现步骤:
- 对每个指令生成 K 个响应
- 用奖励模型对每个响应打分
- 使用最低分作为该指令的整体评分
- 改进: 按类别分别设置阈值(避免全局阈值导致的主题分布偏移)
与原始 RIP 的区别:
- 原始 RIP: 全局阈值(如 50% 分位数)
- 本文改进: 按类别分别过滤,保持主题多样性
自训练方法
推理任务: 使用 GRPO (Group Relative Policy Optimization)
- 基于可验证的规则奖励
- 16 个 rollout,温度 0.6,top-p 0.95
非推理任务: 使用 DPO (Direct Preference Optimization)
- 离线 DPO 和在线 DPO 两种设置
- 在线 DPO 表现最佳
实验结果
实验设置
种子数据:
- 推理任务: s1k 数据集的 893 条可验证推理指令
- 非推理任务: WildChat 的人类指令(按 8 个领域分组)
生成规模:
- 推理任务:生成 10,000 条指令
- 非推理任务:按类别生成,保持分布平衡
评估基准:
- 推理: MATH500, AMC23, AIME24, GPQA-Diamond
- 非推理: AlpacaEval 2.0, Arena-Hard
主要结果
1. 推理任务性能
| 训练数据 | MATH500 | AMC23 | AIME24 | GPQA-D |
|---|---|---|---|---|
| s1k (原始) | 44.6% | - | - | - |
| OpenMathReasoning | 47.5% | - | - | - |
| Self-Instruct | 49.5% | - | - | - |
| CoT-Self-Instruct | 53.0% | +8.4% | +5.2% | +6.1% |
| + Answer-Consistency | 57.2% | +12.6% | +7.8% | +8.3% |
关键发现:
- CoT-Self-Instruct 超越 Self-Instruct 3.5 个百分点
- Answer-Consistency 过滤进一步提升 4.2 个百分点
- 在所有推理基准上都保持一致的优势
2. 非推理任务性能
| 训练数据 | AlpacaEval 2.0 | Arena-Hard |
|---|---|---|
| 人类数据 (WildChat) | 63.1% | - |
| Self-Instruct | 47.4% | - |
| CoT-Self-Instruct | 53.9% | +6.5% |
| + RIP 过滤 | 54.7% | +7.3% |
| + 在线 DPO | 67.1% | +12.0% |
关键发现:
- CoT-Self-Instruct 超越 Self-Instruct 6.5 个百分点
- RIP 过滤提供额外提升
- 在线 DPO 训练后超越人类数据(67.1% vs 63.1%)
3. 消融实验
CoT vs 无 CoT:
| 方法 | 指令生成 | 答案生成 | MATH500 |
|---|---|---|---|
| Self-Instruct | ❌ | ❌ | 49.5% |
| 变体 | ❌ | ✅ | 50.8% |
| CoT-Self-Instruct | ✅ | ✅ | 53.0% |
发现: CoT 对指令生成的贡献大于答案生成
CoT 长度分析:
| CoT 类型 | 平均长度 | MATH500 |
|---|---|---|
| 短链 CoT | ~100 tokens | 51.2% |
| 长链 CoT | ~500 tokens | 53.0% |
发现: 更长的推理链带来更好的生成质量
AI 分析方法亮点
问题定位精准: 针对合成数据质量不稳定的核心问题——现有 Self-Instruct 方法直接生成指令,缺少规划步骤,导致生成的数据复杂度和质量波动大,难以保证训练效果
方法创新: 将 CoT 从”解题工具”扩展为”生成规划工具”,让 LLM 先分析种子指令的属性(领域、复杂度、目的),再制定生成计划;提出双重质量保障机制(CoT 生成 + Answer-Consistency/RIP 过滤),效果提升 7.7%
实用性强: 合成数据成本远低于人类标注,小团队也能训练高性能模型;只需少量种子指令即可启动,可快速生成特定领域的训练数据;在 MATH500 等基准上超越现有数据集,在线 DPO 训练后性能达 67.1%,超越人类标注数据(63.1%)
总结
CoT-Self-Instruct 通过将思维链引入数据生成过程,实现了合成数据质量的显著提升。
关键要点:
- CoT 规划: 先分析种子指令,再生成新指令,质量提升 3.5%
- Answer-Consistency: 推理任务过滤,额外提升 4.2%
- RIP 过滤: 非推理任务过滤,保持主题多样性
- 最终效果: 在推理和非推理任务上都超越现有方法,合成数据首次超越人类标注数据
这项研究为 LLM 训练提供了一种高效、低成本的数据生成方案,特别适合资源受限的场景。未来的工作可以探索更高效的 CoT 生成策略和更广泛的答案类型支持。
参考链接
- 📄 论文原文