Bi-Encoder与Cross-Encoder对比分析
Bi-Encoder与Cross-Encoder对比分析
Bi-Encoder和Cross-Encoder是自然语言处理中用于文本匹配的两种主要模型架构,它们在处理方式、效率和应用场景上存在显著差异。以下是它们的详细对比:
1. 核心区别
- Bi-Encoder(双编码器)
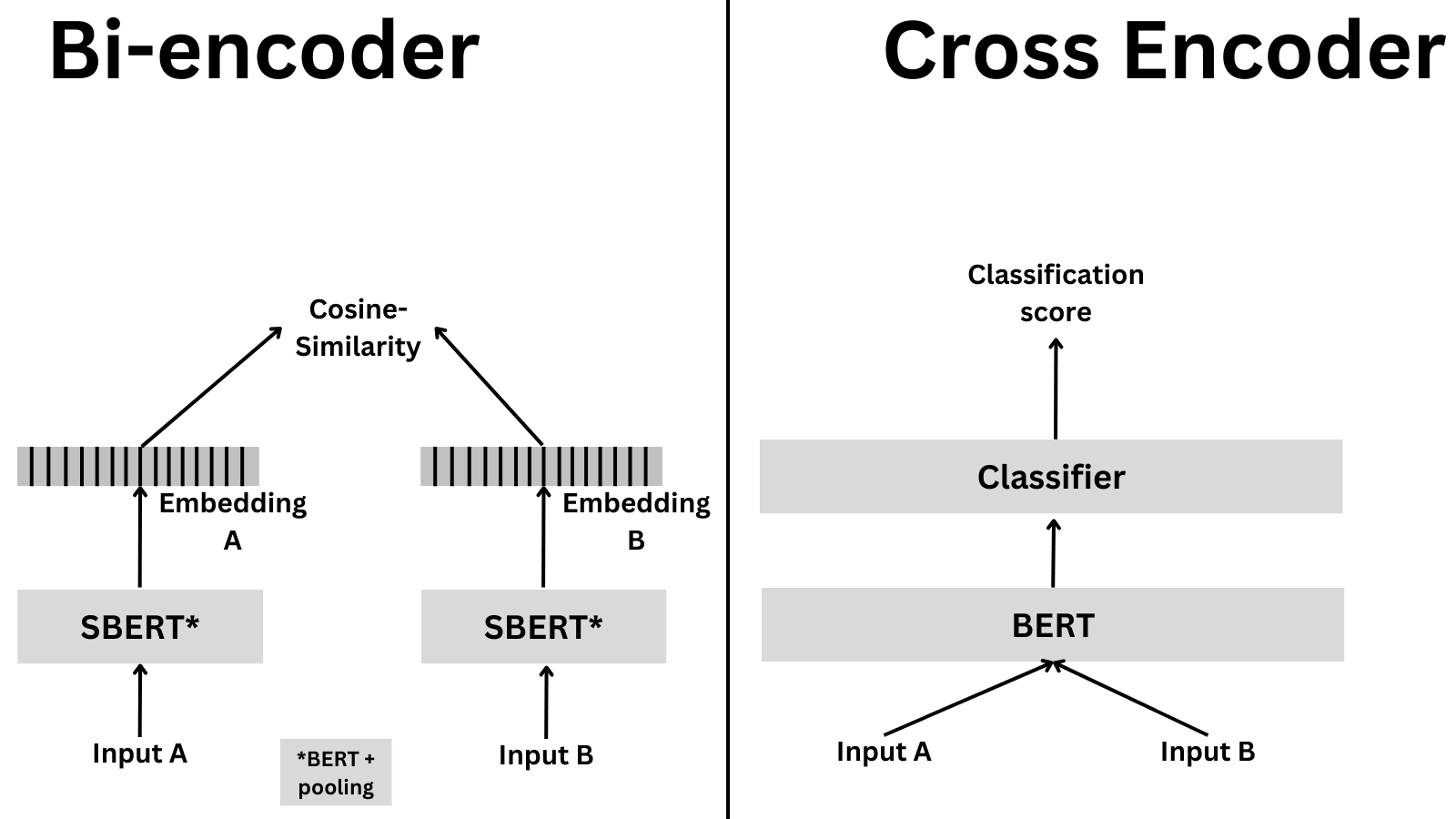
- 处理方式:分别对两个输入文本进行独立编码,生成各自的向量表示,再通过相似度计算(如点积、余弦相似度)进行比较。
- 结构:通常共享参数(如Sentence-BERT),使用同一个编码器分别处理两个文本,输出向量后计算相似度。
- 交互性:无直接交互,仅在向量空间中进行相似度匹配。
- Cross-Encoder(交叉编码器)
- 处理方式:将两个文本拼接后输入模型,通过交叉注意力机制联合编码,直接输出相似度分数或分类结果。
- 结构:单编码器处理拼接后的文本,利用[CLS]标记或特定输出层生成预测结果。
- 交互性:充分捕捉文本间的细粒度交互信息。
2. 优缺点对比
| 特性 | Bi-Encoder | Cross-Encoder |
|---|---|---|
| 计算效率 | 高(可预计算候选向量,适合大规模检索) | 低(需实时计算,复杂度随数据量线性增长) |
| 准确性 | 较低(独立编码丢失交互信息) | 较高(联合编码捕捉细粒度关系) |
| 适用场景 | 召回阶段、实时检索 | 精排阶段、高精度匹配 |
| 训练数据需求 | 需大量负样本(对比学习) | 可直接用正负样本对进行分类/回归 |
| 延迟敏感性 | 低延迟,适合在线服务 | 高延迟,适合离线或小规模精排 |
3. 典型应用场景
- Bi-Encoder
- 大规模检索:搜索引擎、推荐系统的召回阶段。
- 语义相似度初步筛选:快速从海量数据中筛选候选(如问答系统)。
- 实时应用:需要低延迟响应的场景(如聊天机器人)。
- Cross-Encoder
- 精细排序:对Bi-Encoder召回的结果进行重排(如MS MARCO文档排序)。
- 高精度匹配:短文本对分类(如自然语言推理、重复问题检测)。
- 小样本学习:数据量较少时,利用交互信息提升性能。
4. 训练策略
- Bi-Encoder
- 损失函数:对比损失(InfoNCE)、三元组损失。
- 训练目标:拉近正样本对的向量距离,推远负样本对。
- 数据增强:依赖负采样策略(如困难负样本挖掘)。
- Cross-Encoder
- 损失函数:交叉熵(分类任务)、均方误差(回归任务)。
- 训练目标:直接预测相似度分数或类别标签。
- 输入格式:拼接文本(如
[CLS]文本1[SEP]文本2[SEP])。
5. 实际应用中的结合
- 混合架构:
- 召回阶段:用Bi-Encoder快速筛选Top-K候选(如1000个结果)。
- 排序阶段:用Cross-Encoder对Top-K结果精排,选出最终答案。
- 优势:兼顾效率与精度,广泛应用于工业级系统(如搜索引擎、广告推荐)。
6. 示例模型
- Bi-Encoder:Sentence-BERT、DPR(Dense Passage Retrieval)。
- Cross-Encoder:BERT-NSP(Next Sentence Prediction)、RoBERTa用于STS任务。
总结
- 选择Bi-Encoder:当需要快速处理大规模数据且对延迟敏感时。
- 选择Cross-Encoder:当任务需要高精度匹配且计算资源充足时。
- 最佳实践:结合两者优势,构建“召回+精排”的流水线,平衡效率与效果。
本文由作者按照 CC BY 4.0 进行授权